《Trajectory Clustering- A Partition-and-Group Framework》学习笔记
原文提出一种轨迹分割方法:在原轨迹中选取一些特征点,利用特征点的连线来近似原轨迹。特征点是多指轨迹中变化较大的点。 partition用特征点之间的线段表示。
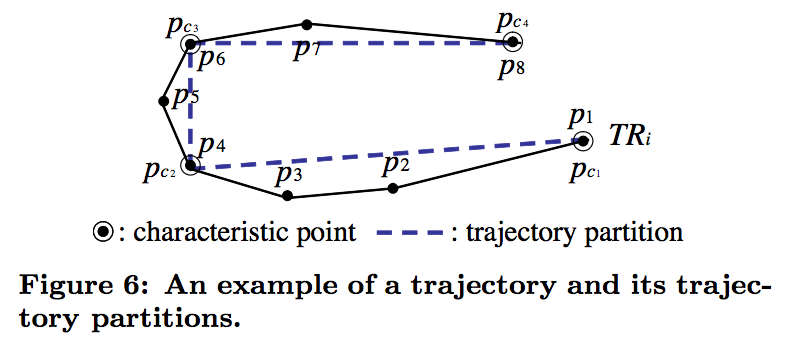
对轨迹的分段要保证两个性质:准确性和简洁性。 准确性是指特征点不能太少,否则不足以概括轨迹特征; 简洁性是指特征点要利用尽可能少的点来概括轨迹特征。 这两个特性相互矛盾,因此算法要能够很好地平衡这两个特性。原文采用信息压缩中广泛采用的MDL(Minimum Description Length)原则来做平衡。
最小描述长度(MDL),原理是 Rissane 在研究通用编码时提出的。其基本原理是对于一组给定的实例数据D,如果要对其进行保存,为了节省存储空间,一般采用某种模型H对其进行编码压缩,然后再保存压缩后的数据。同时,为了以后正确恢复这些实例数据,将所用的模型也保存起来。所以需要保存的数据长度(比特数)等于这些实例数据进行编码压缩后的长度加上保存模型所需的数据长度,将该数据长度称为总描述长度。最小描述长度(MDL)原理就是要求选择总描述长度最小的模型。
MDL原则包含两个部分:
- L(H):描述压缩模型(或编码方式)所需要的长度
- L(D/H):描述利用压缩模型所编码的数据所需要的长度
原文中对两部分的定义如下:
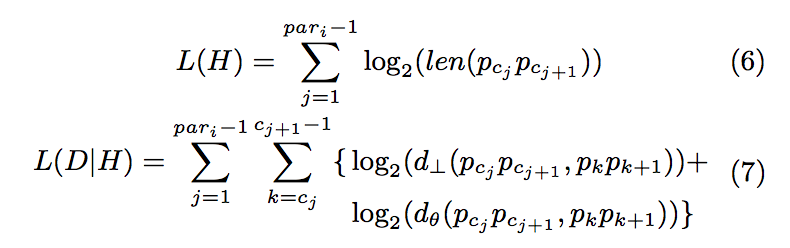
L(D/H)中没有包含水平距离是因为对于闭合的两条线段,其水平距离为零.
例如:
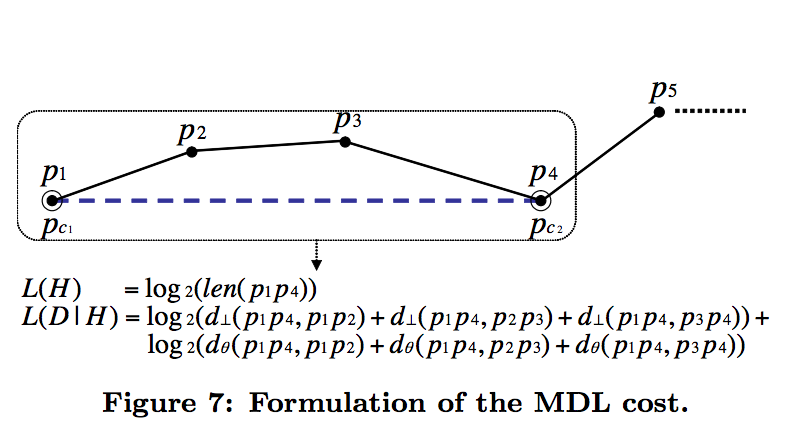
原文又定义了两个概念。MDLpar(pi,pj)表示若点pi、pj为仅有的特征点时所需要的MDL开销,即L(H)+L(D/H);MDLnopar(pi,pj)表示pi、pj之间没有特征点时的MDL开销,即退化为原始路径。具体来讲,MDLnopar(pi,pj)的L(D/H)部分为0(因为没有特征点所以partition跟原轨迹没有距离),L(H)部分为log2(原轨迹各线段的长度之和)。对于给定的一条线段,算法选择其特征点的标准是该点为特征点的MDL开销要小于不选择其作为特征点的MDL开销。
算法流程如下:

我模拟的结果如下,红色代表特征点:
