一例后端服务请求超时
业务服务A,概率性出现批量地请求消息服务超时报错:error:Post http://message-api.in.codoon.com:4119/message_api/batch_post: net/http: request canceled (Client.Timeout exceeded while awaiting headers)
消息服务本身没有任何错误信息可查,分析服务A代码,发现其某场景下会批量给一千个用户发消息,导致消息服务处理超时。知道地方就很好改了,将每次处理数量限制在100个:
@@ -193,15 +193,33 @@ func DoNotify(userIds []string, source, targetId int, targetTime int64) {
defer sp.Finish()
ctx := context.WithValue(context.Background(), trace.CDTCtxKey, sp.Context())
+ const MAX = 100
+
syncData := map[string]interface{}{
"source": source,
"target_id": strconv.Itoa(targetId),
"target_time": targetTime,
}
- rsp, err := external.BatchSyncNotify(ctx, userIds, syncData)
- if err != nil {
- clog.Logger.Error("DoNotify error:%s rsp:%+v", err, rsp)
+
+ if len(userIds) == 1 {
+ rsp, err := external.SingleSyncNotify(ctx, userIds[0], syncData)
+ if err != nil {
+ clog.Logger.Error("DoNotify error:%s rsp:%+v", err, rsp)
+ }
+ } else {
+ for i := 0; i < len(userIds); {
+ j := i + MAX
+ if j > len(userIds) {
+ j = len(userIds)
+ }
+ us := userIds[i:j]
+ rsp, err := external.BatchSyncNotify(ctx, us, syncData)
+ if err != nil {
+ clog.Logger.Error("DoNotify error:%s rsp:%+v", err, rsp)
+ }
+ i = j
+ }
}
- clog.Logger.Debug("DoNotify success user_num:%d rsp:%+v", len(userIds), rsp)
+
return
}一例CPU报警
业务服务B,从23号上线之后到26号运维发现CPU使用一直在呈上涨趋势。
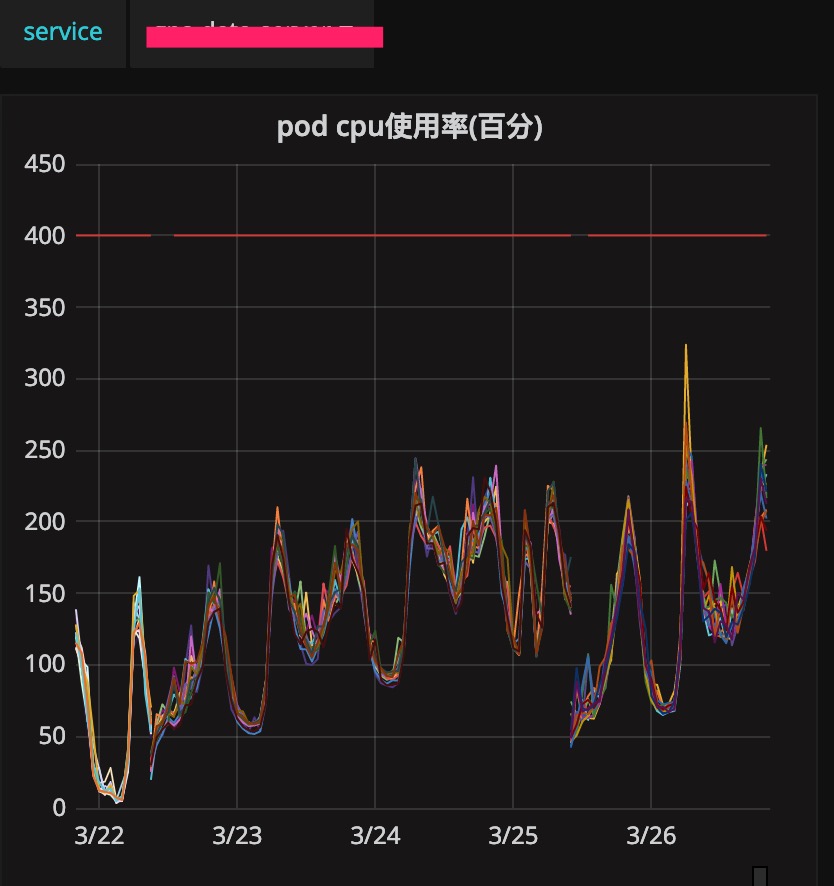
分析pprof如下:

runtime.siftdownTimer是定时器相关逻辑。对比一下上线代码可知是新引入的定时器的问题。从99.9%CPU浅谈Golang的定时器实现原理对此讲解的比较清楚。最重要的概念是:time.After只会创建一个单次的timer,而time.Tick创建的是一个永久循环的timer。故前者不必须手动关闭,但是后者必须在不用时手动关闭掉:
@@ -1304,12 +1304,13 @@ func (b *BatchTask) Run(timeout time.Duration) (timed bool) {
}
b.TaskList.Range(p)
after := time.After(timeout)
- ticker := time.Tick(time.Millisecond * 200)
+ ticker := time.NewTicker(time.Millisecond * 200)
+ defer ticker.Stop()
for {
select {
case <-after:
return true
- case <-ticker:
+ case <-ticker.C:
i := 0
b.TaskList.Range(func(k, v interface{}) bool {
i++一例MEM报警
业务服务C,基本每天都有一两次内存超高报警,超过运维设置的1G的限制:

分析pprof如下:

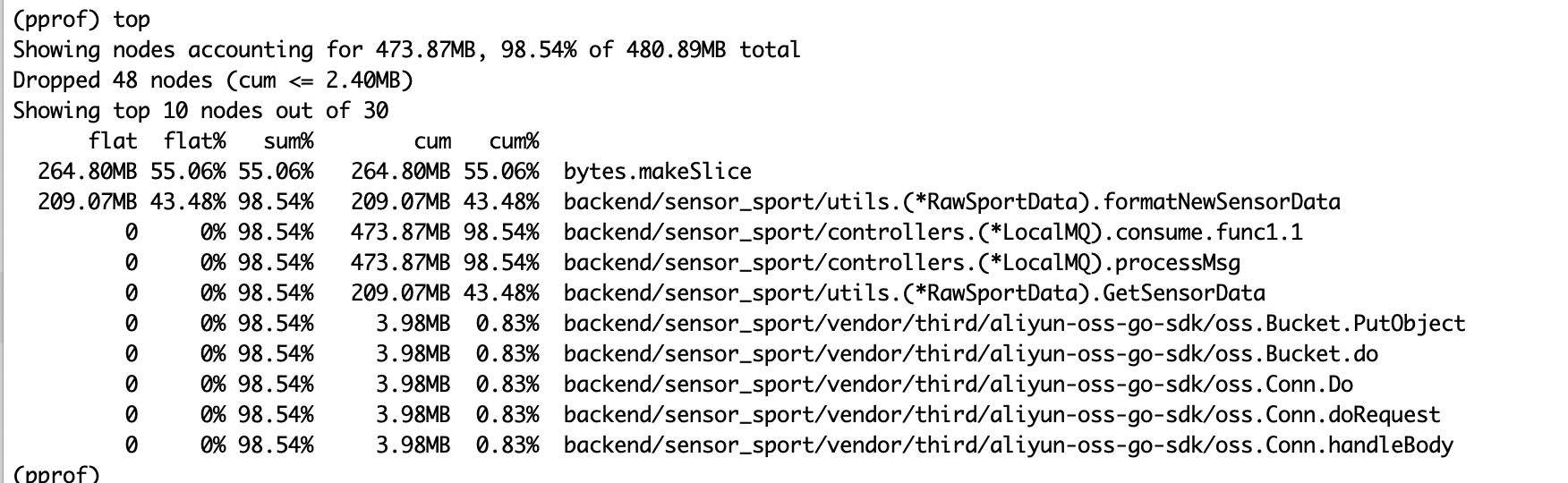

可以看到是文件操作中申请了大量的内存,然后再json序列化使得情况恶劣翻倍。首先针对疑点处加日志,发现问题时间有超大文件的出现:
[webteam@log go_log]$ grep 'sensors in' sensor_sport.log|grep '2019-03-27 21:'|awk '{if ($6 > 1000000) print $0}'
business-7 [2019-03-27 21:47:59.903][INFO][sensor_sport][goroutine:2051056/634][raw_sport_data.go:226] route:e917d86e-5096-11e9-b7be-0169ba01d0b8 with 1619852 sensors in 206 files
business-5 [2019-03-27 21:56:16.421][INFO][sensor_sport][goroutine:2496050/431][raw_sport_data.go:226] route:deb7e689-5097-11e9-816a-0169ba034ba0 with 8474681 sensors in 1067 files
从日志可以看出一个大文件最多有8474681个对象,每个32byte,仅存放数据就要占用200+M,算上json序列化以及更早的解析protobuf的步骤可能耗用内存翻几番。
但是从业务上来说这种超大文件本身是不合规的,故在业务上过滤此等文件。另外还尝试了内存池https://github.com/funny/slab的写法:
package utils
import (
"backend/framework/log"
"sync"
)
type RawMem [4]int64
var GUseMemPool bool
var MinSize int = 100
var MaxSize int = 100 * 1024
var MaxSensor int = 1000000
var MemPool *SyncPool
func InitPool() {
MemPool = NewSyncPool(MinSize, MaxSize, 2)
log.Info("init pool")
}
// SyncPool is a sync.Pool base slab allocation memory pool
type SyncPool struct {
classes []sync.Pool
classesSize []int
minSize int
maxSize int
}
// NewSyncPool create a sync.Pool base slab allocation memory pool.
// minSize is the smallest chunk size.
// maxSize is the lagest chunk size.
// factor is used to control growth of chunk size.
func NewSyncPool(minSize, maxSize, factor int) *SyncPool {
n := 0
for chunkSize := minSize; chunkSize <= maxSize; chunkSize *= factor {
n++
}
pool := &SyncPool{
make([]sync.Pool, n),
make([]int, n),
minSize, maxSize,
}
n = 0
for chunkSize := minSize; chunkSize <= maxSize; chunkSize *= factor {
pool.classesSize[n] = chunkSize
pool.classes[n].New = func(size int) func() interface{} {
return func() interface{} {
buf := make([]RawMem, size)
return &buf
}
}(chunkSize)
n++
}
return pool
}
// Alloc try alloc a []byte from internal slab class if no free chunk in slab class Alloc will make one.
func (pool *SyncPool) Alloc(size int) []RawMem {
if size <= pool.maxSize {
for i := 0; i < len(pool.classesSize); i++ {
if pool.classesSize[i] >= size {
mem := pool.classes[i].Get().(*[]RawMem)
return (*mem)[:size]
}
}
}
return make([]RawMem, size)
}
// Free release a []byte that alloc from Pool.Alloc.
func (pool *SyncPool) Free(mem []RawMem) {
if size := cap(mem); size <= pool.maxSize {
for i := 0; i < len(pool.classesSize); i++ {
if pool.classesSize[i] >= size {
pool.classes[i].Put(&mem)
return
}
}
}
}从压测的效果来看不错:
func BenchmarkPool(b *testing.B) {
pool := NewSyncPool(MinSize, MaxSize, 2)
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
size := rand.Intn(1024 * 100)
ret := &SensorData1{}
ret.GsPoints = pool.Alloc(size)
if len(ret.GsPoints) != size {
b.Fatal("not equal")
}
for i := 0; i < size; i++ {
ret.GsPoints[i] = RawMem{int64(size), int64(size), int64(size), int64(size)}
}
for i := 0; i < size; i++ {
m := RawMem{int64(size), int64(size), int64(size), int64(size)}
if ret.GsPoints[i] != m {
b.Fatal("not equal m")
}
}
pool.Free(ret.GsPoints)
}
})
}
func BenchmarkMake(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
size := rand.Intn(1024 * 100)
ret := &SensorData1{}
ret.GsPoints = make([]RawMem, size)
if len(ret.GsPoints) != size {
b.Fatal("not equal")
}
for i := 0; i < size; i++ {
ret.GsPoints[i] = RawMem{int64(size), int64(size), int64(size), int64(size)}
}
for i := 0; i < size; i++ {
m := RawMem{int64(size), int64(size), int64(size), int64(size)}
if ret.GsPoints[i] != m {
b.Fatal("not equal m")
}
}
}
})
}C02S259EFVH3:utils baixiao$ GOGC=off go test -cpu 1,8 -run none -bench .
goos: darwin
goarch: amd64
pkg: backend/sensor_sport/utils
BenchmarkPool 5000 312012 ns/op
BenchmarkPool-8 5000 252566 ns/op
BenchmarkMake 2000 1843596 ns/op
BenchmarkMake-8 1000 1238463 ns/op
PASS
ok backend/sensor_sport/utils 9.276s
在实际项目中有待考察。