建议先自行学习 Kafka 的基础知识内容。
通常我们讲 Kafka 是一个高可靠、高吞吐的分布式数据流系统。本文只讨论其高吞吐的特性。思考几个问题:
- Kafka 的哪些设计促成了其高吞吐的特性
- 对比一般的消息队列(RabbitMQ等),Kafka 怎么做到高吞吐的情况下还能保存大量消息
Partion 模型带来的高吞吐
Topic 下的 Partion 概念,可以横向扩展,部署到多台服务器上。故此不论网络 I/O 还是服务器的本地 I/O 都能扩展,特别是针对消费端需要高 CPU 计算的场景,通过增加 Partion 数量和对应 Consumer Group 中 Consumer 的数量,来提升系统的吞吐量。
生产环节:

消费环节:

配合下面的机制,Partion 可以说是 Kafka 并行起来的基础。Partion 内部是由 Segment 文件组成的,这点和 Elasticsearch 相似。
Broker 层面
磁盘顺序读写
一般印象中,内存读写肯定比磁盘读写快。事实上磁盘可能比人们预想的更慢、或者更快,取决于怎么使用它。一个良好设计的磁盘结构通常和我们的网络 I/O 一样快。
磁盘的模型图:
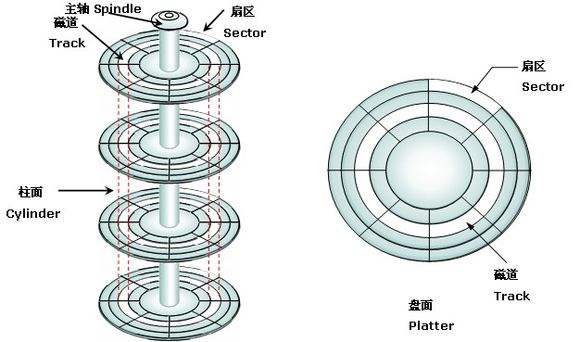
说起磁盘慢的主要原因在于其寻道操作,在于磁盘的磁头在盘面上的物理位移。我们来看磁盘调度算法里面经典的 SCAN 算法(又称电梯算法)如下图所示:

例如,磁盘请求队列中的请求顺序分别为 55、58、39、18、90、160、150、38、184,磁头初始位置是 100 磁道。釆用 SCAN 算法时,不但要知道磁头的当前位置,还要知道磁头的移动方向,假设磁头沿磁道号增大的顺序移动,则磁头的运动过程如上图所示。磁头共移动了( 50+10+24+94+32+3+16+1+20 ) = 250 个磁道,平均寻找长度 = 250/9 = 27.8。那么对于我们最先想要访问的 55 号位置,要等到磁头第六次真实位移后才能访问到。
如此可见顺序读写对磁盘性能的重要性。如果我们只进行顺序读写,则能极大提高读写效率,甚至能高于内存的随机访问。更多的速度对比在文章《ACM Queue article》中,结论如图:

故此,Producer 生产消息是不断追加到磁盘文件的,Consumer 消费消息也是从磁盘顺序读取的,都充分利用到了磁盘的顺序读写性能。
利用Page Cache
Kafka 利用到了现代操作系统的特性,Page Cache。Page Cache 是通过将磁盘中的数据缓存到内存中,从而减少磁盘 I/O 操作,从而提高性能。此外,还要确保在 Page Cache 中的数据更改时能够被同步到磁盘上,后者被称为 page 回写(page writeback)。
当上层有写操作时,操作系统只是将数据写入 Page Cache ,同时标记 Page 属性为 Dirty。当读操作发生时,先从 Page Cache 中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。实际上 Page Cache 是把尽可能多的空闲内存都当做了磁盘缓存来使用。同时如果有其他进程申请内存,回收 Page Cache 的代价又很小,所以现代的 OS 都支持 Page Cache。
相比于应用程序自己(Kafka 是 Java 程序)做 cache, 使用 Page Cache 有如下优势:
- 操作系统会自行将连续的小量写操作批量处理为物理写操作,从而提高 IO 吞吐。
- 操作系统会尽量将写操作重新排序以减小写磁盘时的磁头偏移量,从而提高 IO 吞吐。
- 所有空闲内存都自动构成 Page Cache。
- 如果在应用程序 Heap 内管理缓存,JVM 的 GC 线程会频繁扫描 Heap 空间,带来不必要的开销。如果 Heap 过大,执行一次 Full GC 对系统的可用性来说将是极大的挑战。
- 所有在 JVM 内的对象都不免带有一个 Object Overhead(千万不可小视),内存的有效空间利用率会因此降低。
- 所有的 In-Process Cache 在OS中都有一份同样的 PageCache。所以通过只在PageCache 中做缓存至少可以提高一倍的缓存空间。
- 如果 Kafka 重启,所有的 In-Process Cache都会失效,而 OS 管理的 PageCache 依然可以继续使用。
底层 zero-copy 技术带来的高吞吐
首先来看一下传统的通过网络读取文件涉及到的传输过程:

涉及到四次内存拷贝过程:
-
DMA data from disk to read buffer
-
Copy data from read buffer to application buffer
-
Copy data from application buffer to socket buffer
-
DMA buffer from socket buffer to network
注:read buffer 为 page cache,socket buffer 为内核 socket buffer。
并涉及到四次上下文切换:
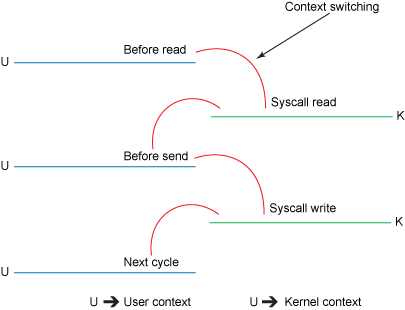
看上去现代操作系统怎么这么蠢?实际上当初设计这一套机制是为了提高性能,利用操作系统内部 kernel buffer:
- read 操作可以利用
readahead cache机制,提前为应用程序准备好数据,当应用程序所需的数据量小于 kernel buffer 时可以显著地提升性能 - write 操作可以异步执行
但实际上 Kafka 的场景是要实现高吞吐的文件数据传输,这种机制就成为了系统瓶颈。
利用 zero-copy 技术
上诉内存拷贝的步骤 2 和 3 看起来都是浪费,因为应用程序并没有对数据进行过加工。实际上,数据可以直接从 read buffer 传输到 socket buffer。在 Linux 系统里面的系统调用 sendfile() 对此进行了支持。
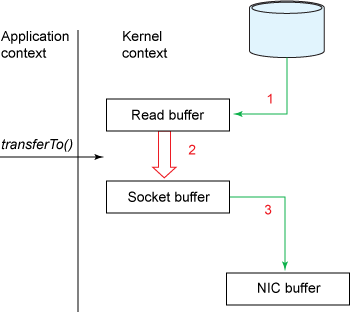
涉及到三次内存拷贝过程:
-
DMA data from disk to read buffer
-
Copy data from read buffer to socket buffer
-
DMA buffer from socket buffer to network
并且使得上线文切换减少到两次:

但这还不是 zero-copy,CPU 依然参与了一次内存拷贝。在网卡支持gather operations特性并且 Linux 2.4 之后,可以进一步优化为:

涉及到两次内存拷贝过程:
-
DMA data from disk to read buffer
-
No data copied to socket buffer, only the descriptors with information about the location and length
-
DMA buffer from read buffer to network
优势和劣势
为了使用 zero-copy,很明显的一点劣势就是应用程序即 Kafka 的 Broker 不能对数据进行二次加工,数据进来是什么样子出去就是什么样子。与此同时的优势就是,Producer 到 Consumer 可以做端到端的压缩,反正中间的 Broker 不能修改数据本身。实际上这种端到端的压缩也是构成高吞吐的原因之一。
综合一下 PageCahce 和 zero-copy
热数据就直接读 PageCahce,冷数据就走 zero-copy,性能都很好,完美!
Producer 层面
批量化处理
为了避免「small I/O」带来的性能损失,Kafka 提出了message set的概念来批量化处理消息。这个简单的优化带来了巨大的性能提升,因为批量化处理带来了更大的网络报文、更大的顺序磁盘操作、更大的连续内存空间,由此 Kafka 将「突发式的随机消息」转变为顺序的消息流提供给下游的 Consumer。
批量化处理使得 Producer 的发送变成了异步,那么为了保证消息的可靠性,Kafka 提供了 ack 的机制:
- 0:这意味着 Producer 无需等待来自 Broker 的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- 1(默认):这意味着 Producer 在 ISR 中的 leader 已成功收到的数据并得到确认后发送下一条消息。如果 leader宕机了 ,则会丢失数据。
- -1(或者是all): Producer 需要等待 ISR 中的所有 follower 都确认接收到数据后才算一次发送完成,可靠性最高。
数据压缩
Kafka 支持数据端到端的压缩,Producer 可以通过 GZIP 或 Snappy 格式对消息集合进行压缩,以减轻网络传输量和磁盘数据量。Producer 压缩之后,在 Consumer 需进行解压,虽然增加了 CPU 的工作,但在对大数据处理上,瓶颈在网络上而不是 CPU ,所以这个成本很值得。
Consumer 层面
pull 模型
到底是用 push 模型还是 pull 模型,不同的系统有不同的选择。Kafka 使用的 pull 模型,这样有助于 Consumer 自行控制消费速度,不会产生消息积压到 Consumer 的情形。
另一个好处是,Consumer 可以根据自身的情况,选择是否批量去 Broker 拉取消息,以增加整体的吞吐。这在 push 模型里就很难办,因为 Broker 很难知道 Consumer 的负载情况从而不知道是否应该批量推送。
针对传统 pull 模型的一个劣势,即如果 Broker 那里没有消息 Consumer 会一直不断尝试获取,Kafka 这里使用了「long polling」长轮询机制。Consumer 在发起一次请求后立即挂起,一直到 Broker 有更新的时候,Broker 才会主动推送信息到 Consumer。 在 Broker 有更新并推送信息过来之前这个周期内,Consumer 不会有新的多余的请求发生,Broker 对此 Consumer 也啥都不用干,只保留最基本的连接信息,一旦 Broker 有更新将推送给 Consumer,Consumer 将相应的做出处理,处理完后再重新发起下一轮请求。
消息确认机制
以往的消息队列为了记录一条消息是否被消费掉,在其 broker 层做了很多工作:
- 记录每条消息的状态,是否发送、是否确认等
- 和 consumer 确认之间的 ACK 机制
- 异常逻辑的处理,比如消息发送了之后一直没有 ACK 确认要怎么处理
相比之下 Kafka 使用了简单的 offset 机制,摒弃了对消息的状态转换。因为每个 Partition 都只有一个 Consumer 在消费,故每个 Consumer 都只需要记录其本身的消费偏移量 offset,简单有效。老版本的 offset 保存在 zookeeper 中,后面改为存放在一个特殊的 Topic 中。
使用 offset 的另一个好处是 Consumer 可以重复去消费,以适配某些场景。