redis 的普通用法不在本文普及,我们谈一谈使用中的几种特殊场景,以及对应办法。
设想这个电商场景,在分布式部署的架构下,我们利用 elasticsearch 作为数据仓库保存商品的适用优惠券信息(也可以用 mysql 打比方),然后用 redis 作为缓存。
缓存穿透
缓存穿透是指用户查询数据,在 elasticsearch 里没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中肯定找不到,每次都要去 elasticsearch 再查询一遍,然后返回空(相当于进行了两次无用的查询)。
一种有效的办法是使用布隆过滤器,将肯定不存在的key在此过滤掉,从而避免对底层存储的压力。
更加暴力的做法是,对 elasticsearch 返回空值的 key,仍然将其缓存为一个我们认定的非法值(比如「empty」)。这样其他的相同请求就能使用到缓存了。当然也要记得在设置有效值后将非法值的缓存清掉。
缓存击穿
缓存击穿是指缓存中的一个 key 失效时,此时针对该 key 有大量请求并发而来,那么会对下游 elasticsearch 造成较大压力。应对的方法和后面的「缓存雪崩」类似。
缓存雪崩
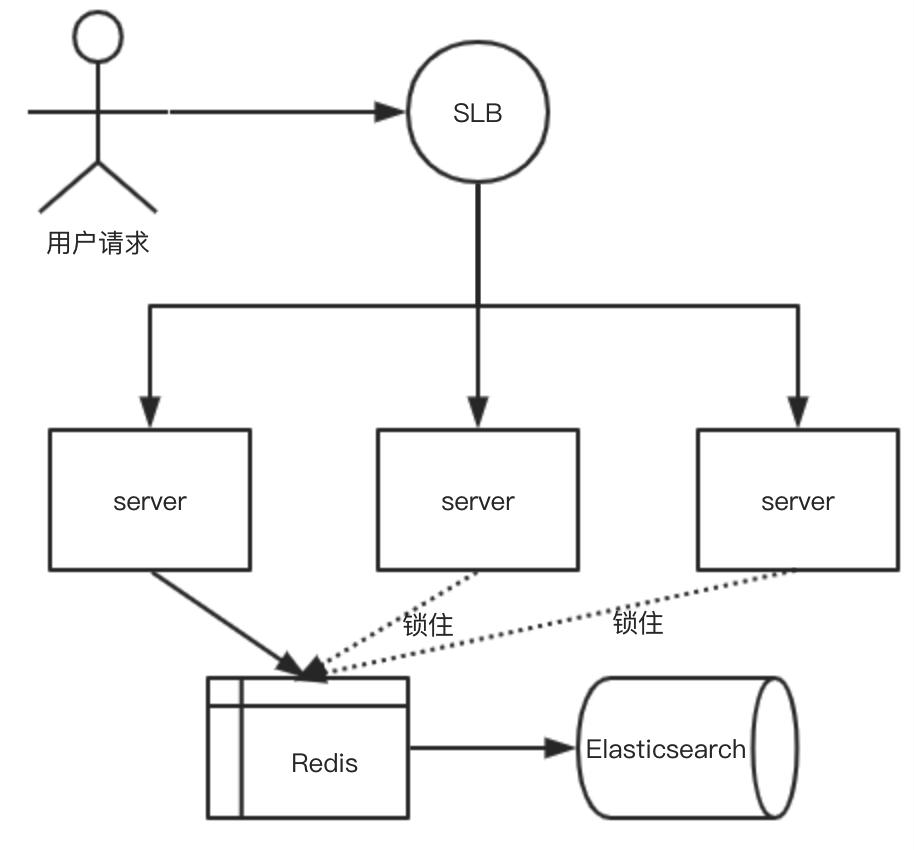
在电商这个场景下,当多个 key 缓存失效的瞬间,如果同时有很高并发的请求到来,那么请求都会打到 elasticsearch 上,对其 CPU 和内存造成巨大的压力,严重时会拖垮其他业务。甚至有可能形成一系列的连锁反应,造成更坏的影响。
正常情况时:

失效瞬间:

应对的办法就是,在缓存数据失效时遭遇并发多请求需要更新时,先用分布式锁锁住该资源,仅让一个服务/进程去更新,以此避免大量请求打到下游数据库。
缓存预加载
如上场景依然可改进。考虑缓存失效时,并发多请求被分布式锁锁住,可能导致这些请求响应不及时,造成慢请求有伤用户体验。
改进的做法是每次在查询缓存后,另起一个协程去查询该 key 的 TTL,如果临近过期(比如定义为小于设置过期时间的1/3)则直接去 elasticsearch 更新数据并刷新缓存,重新设置 TTL。这样平均下来用户的请求基本上不会遇到缓存失效。