最近写的《假如给我百倍流量》讲稿

从三到万。

这是一次务虚的分享,主要想介绍大型后端系统的架构演进方案,以及后续的思考。

世间普适的法则。

这个思想很重要,从CPU芯片到硬件到内核到协议到应用,几乎涵盖了所有计算机领域。本图是缓存领域的多个层级。
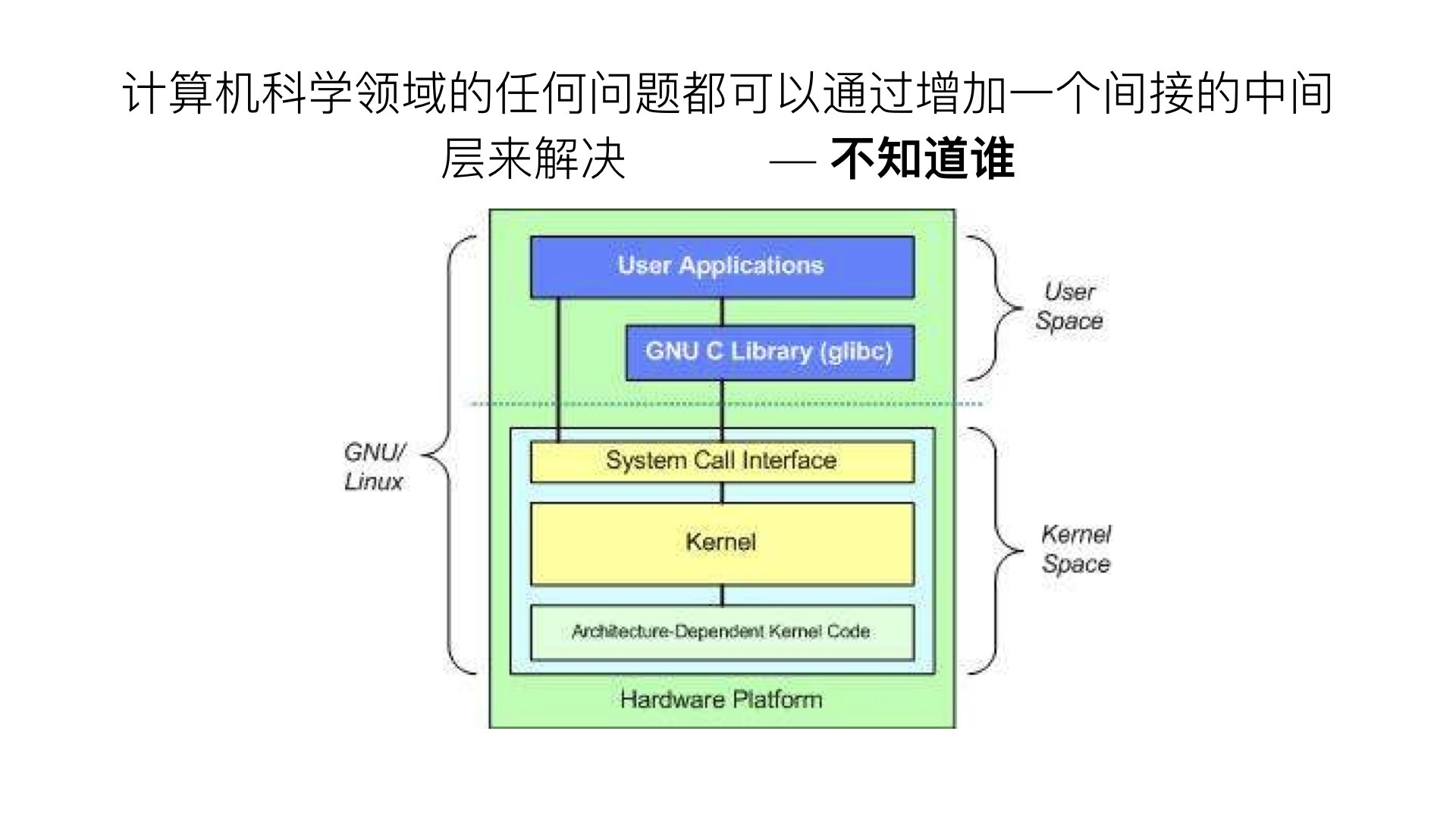
Linux 内核的层级。

OSI 协议的层级。

我们的项目经过天使轮,开工了。

用 Python 开撸,大学生的水平。

项目干得不错,融了 A 轮。用户量增加后服务器 QPS 压力增大。除了平摊 IO 压力,另外一个考虑是为了平滑上线。不能每次上线期间服务都不可用是吧。

一般使用 Nginx。

负载均衡的基本概念。

继续融资 B1 轮,用户量继续增长。缓存也是很基础的优化方案。
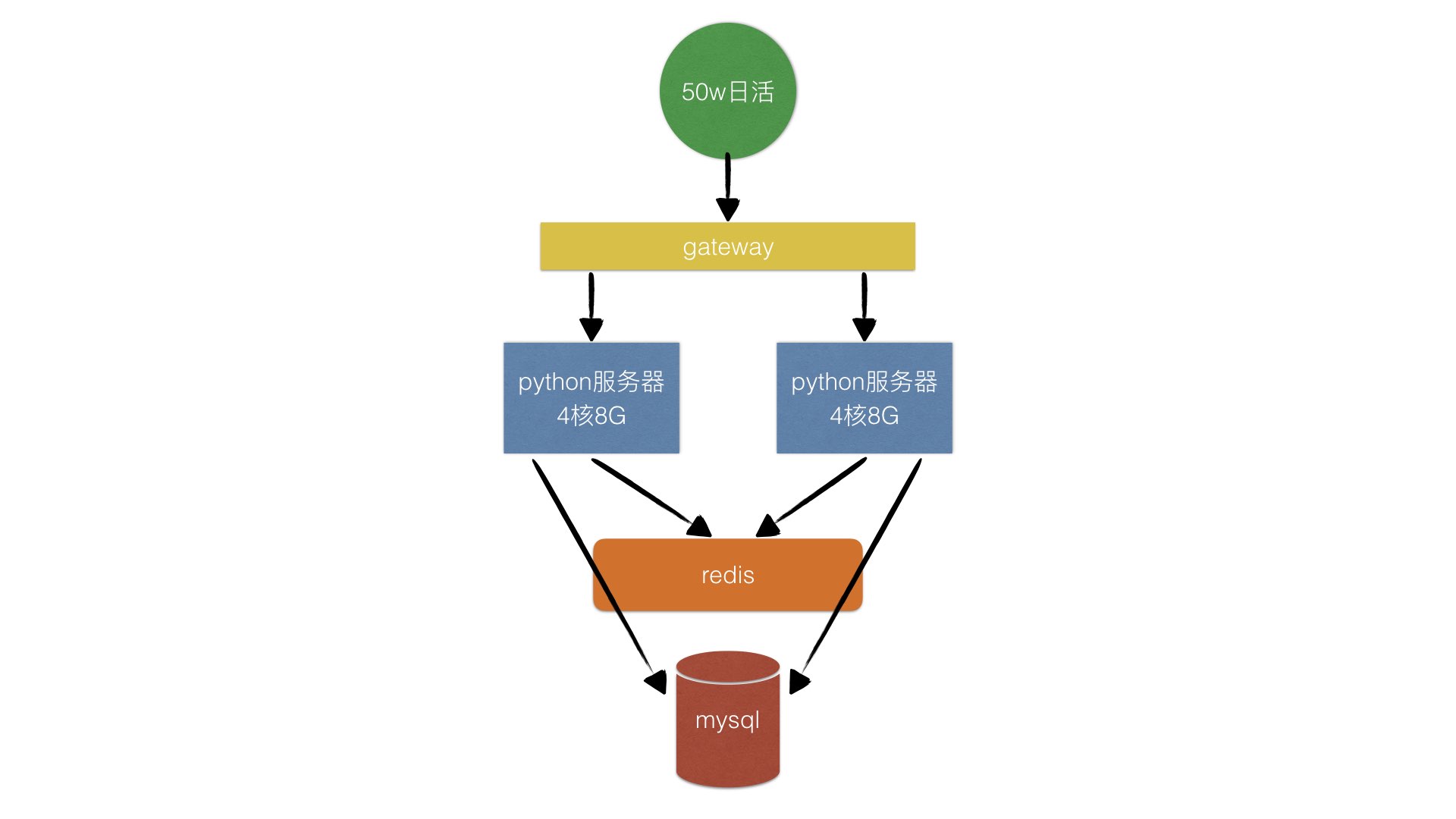
一般使用 Redis。
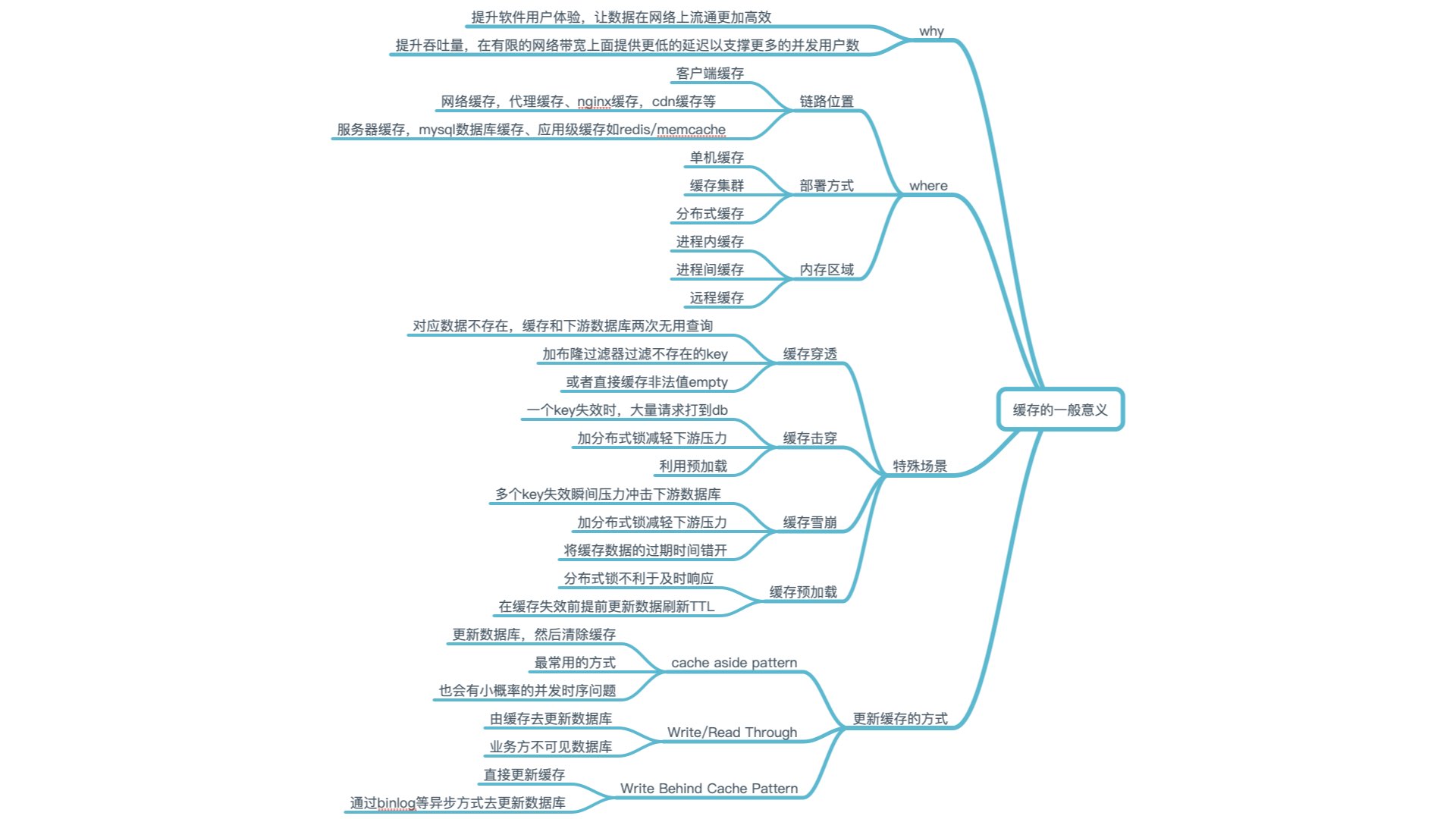
缓存的一般意义。

继续融资 B2 轮,业务增加了 LBS 的功能,需要用到 PostgreSQL + PostGIS 的能力。但是基于地理信息的数据不适合使用缓存,为了平摊压力,引入读写分离。
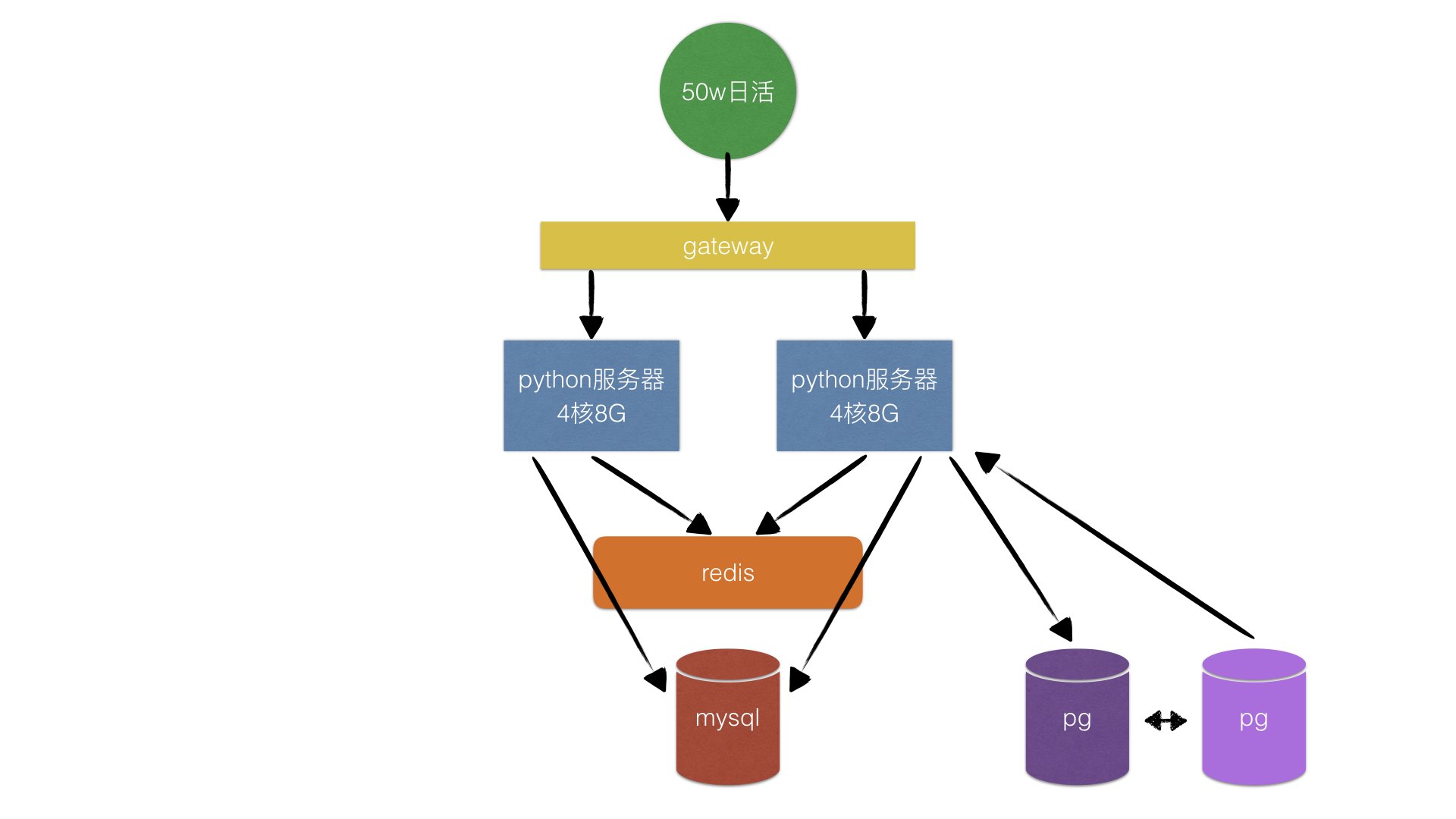
左半边服务器的 pg 连接没有画。

读写分离的基本概念。

项目长足发展,融了 C1 轮的钱,用户量也继续上涨。产品设计了很多提交性的功能,为了减轻数据库的写压力,引入了消息队列,削峰填谷。

右边服务器的 MQ 连接没画。
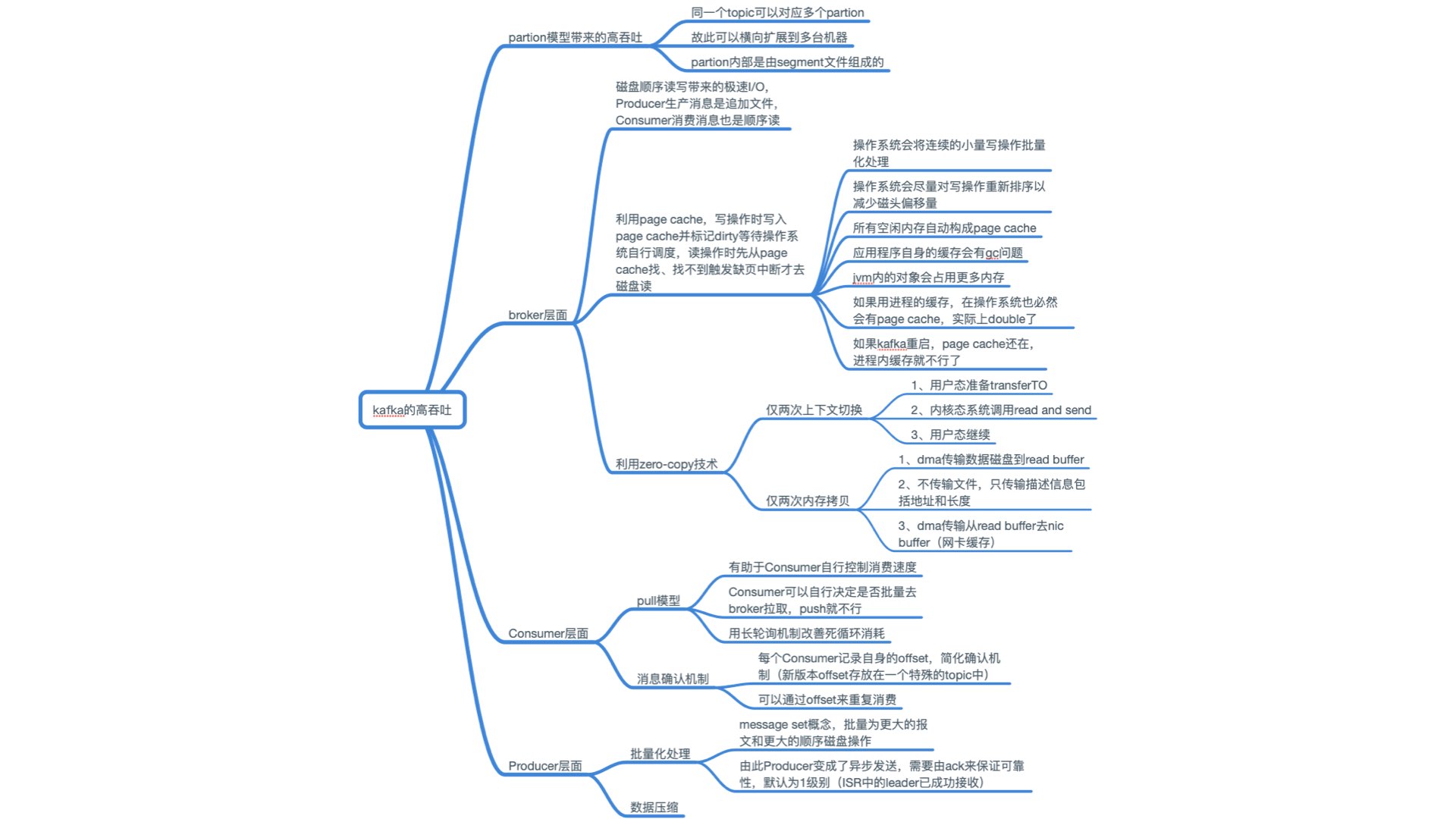
一般使用 Kafka,谈谈 Kafak 高吞吐的实现方式。
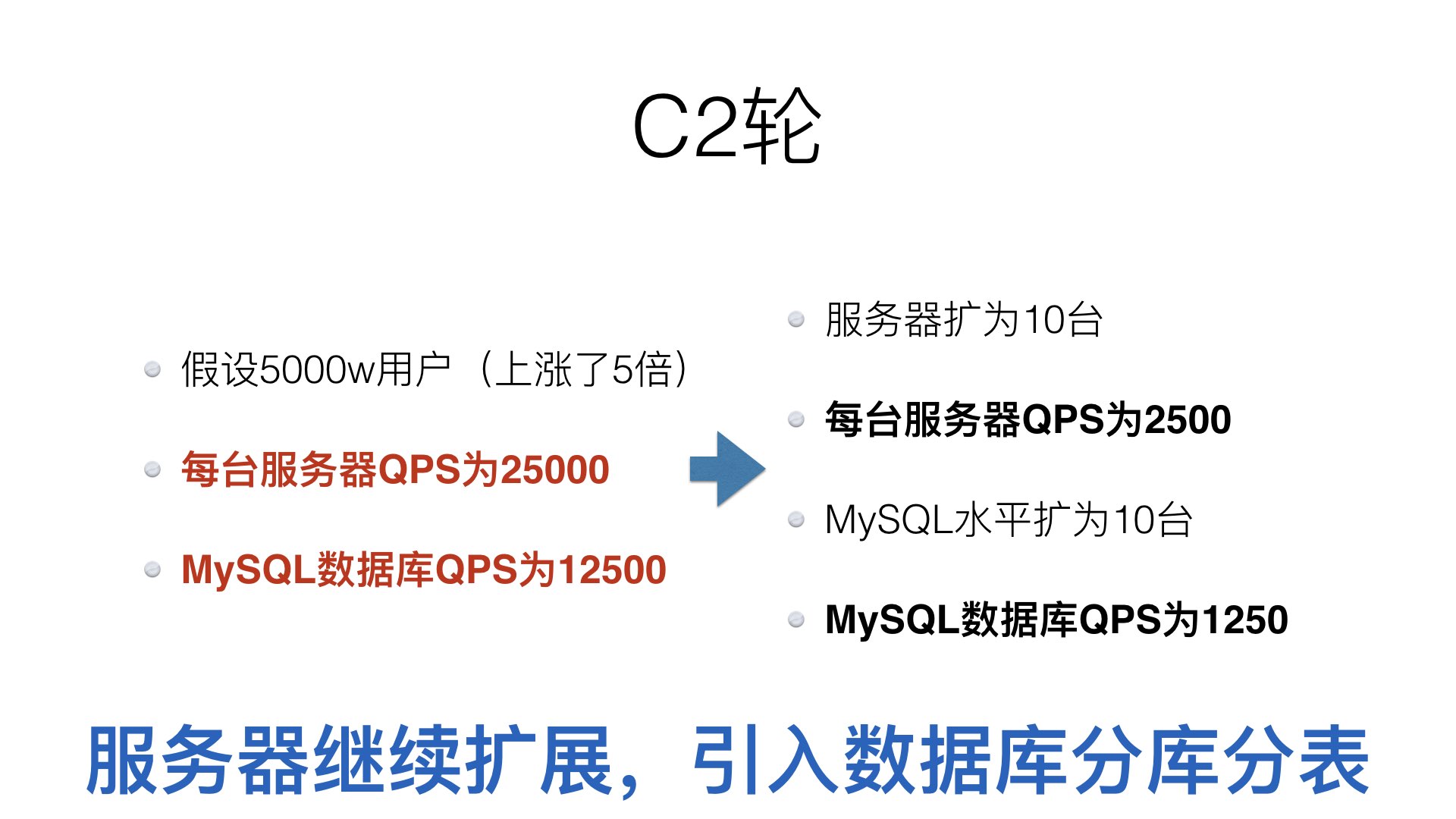
继续融资 C2 轮,用户量继续上涨,数据库单机不论是存储量还是吞吐量都已经是瓶颈。现在开始发大招:数据库分库分表。
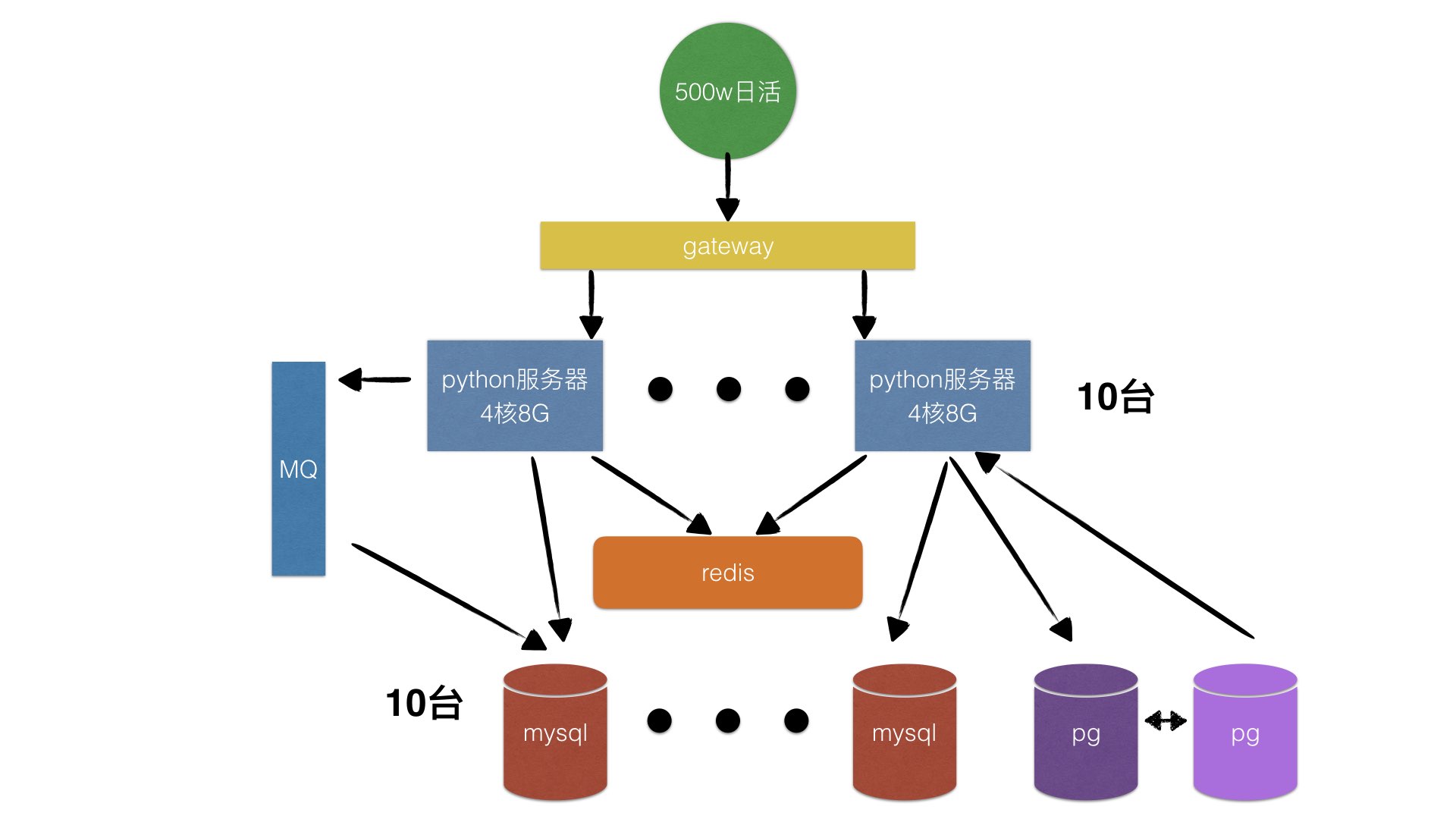
分库分表后的架构。

分库分表后的的概念,记住不要轻易使用,特别是在项目前期不要过度设计。

继续融资 C3 轮,用户量继续上涨。现有架构已经 hold 不住了。
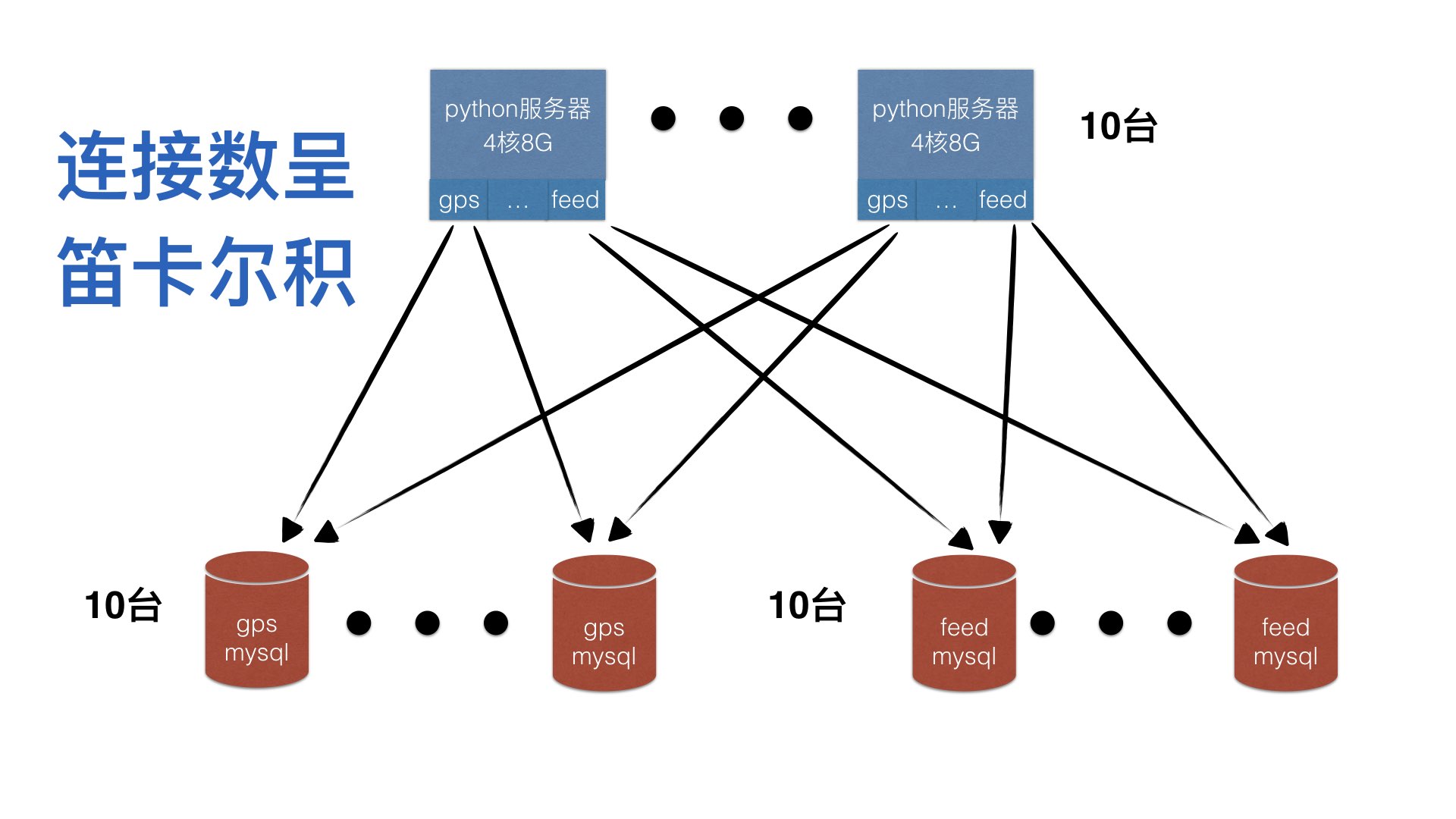
首先是数据库连接数吃紧。

无法做资源隔离,作为一个开发,可能自己的功能没有问题,但是数据库被别人拖挂,服务本身也可能被别人拖挂。
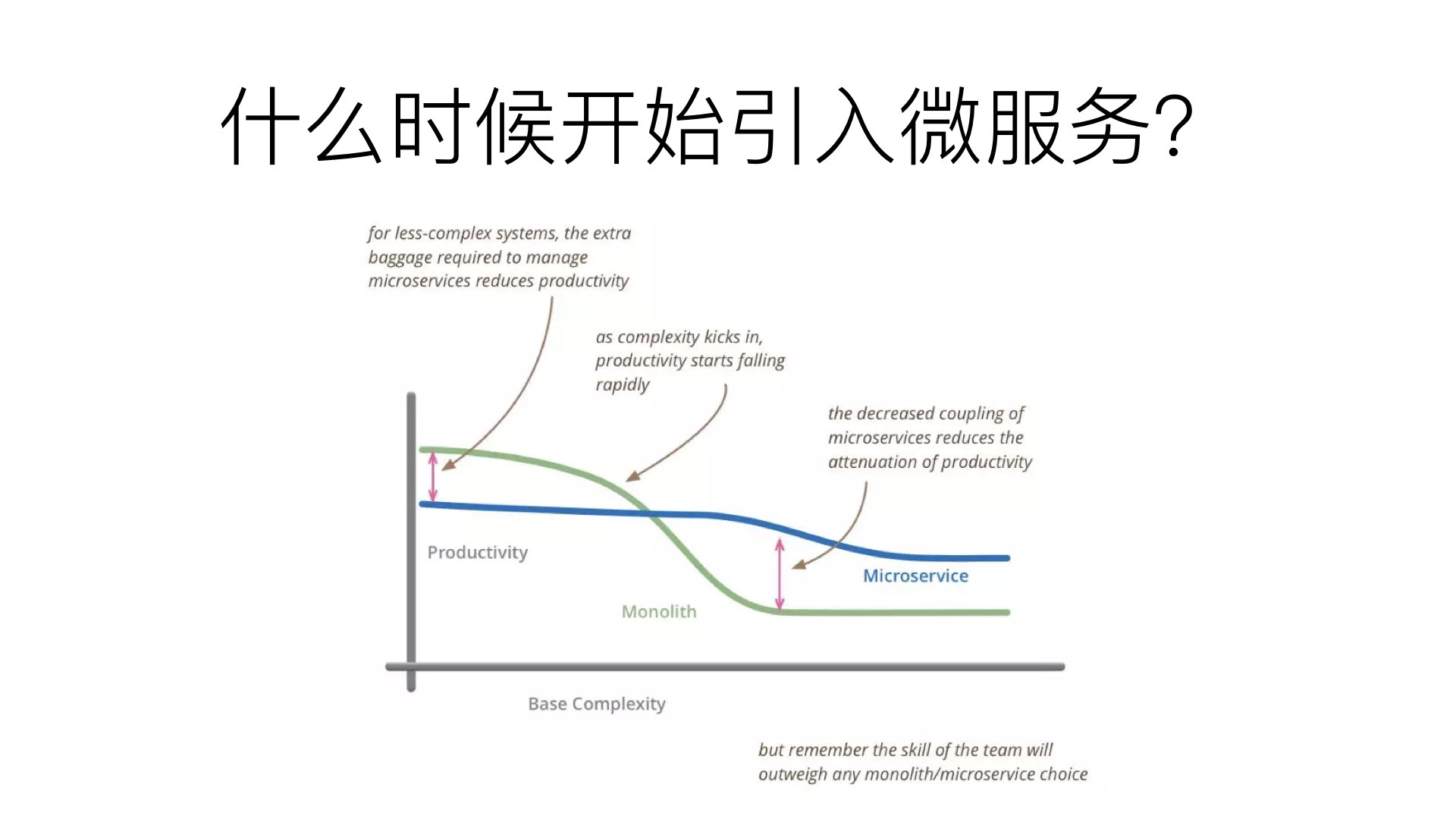
业务越多,整体架构越复杂,微服务带来的收益越大。 过早引入反而是增加开发和运维的工作。

数据库连接数减少。

整个身心都清爽了。

如果一个人负责太多微服务,还不如他写到一个服务里面。

胜利在前方,但是感觉架构又拖了后腿。

Google 爸爸已经帮你准备好了。

不管什么语言什么框架写的应用(Go, Python, Node.js),Kubernetes 都可以在任何环境中安全的启动它,物理服务器、虚拟机、云环境。
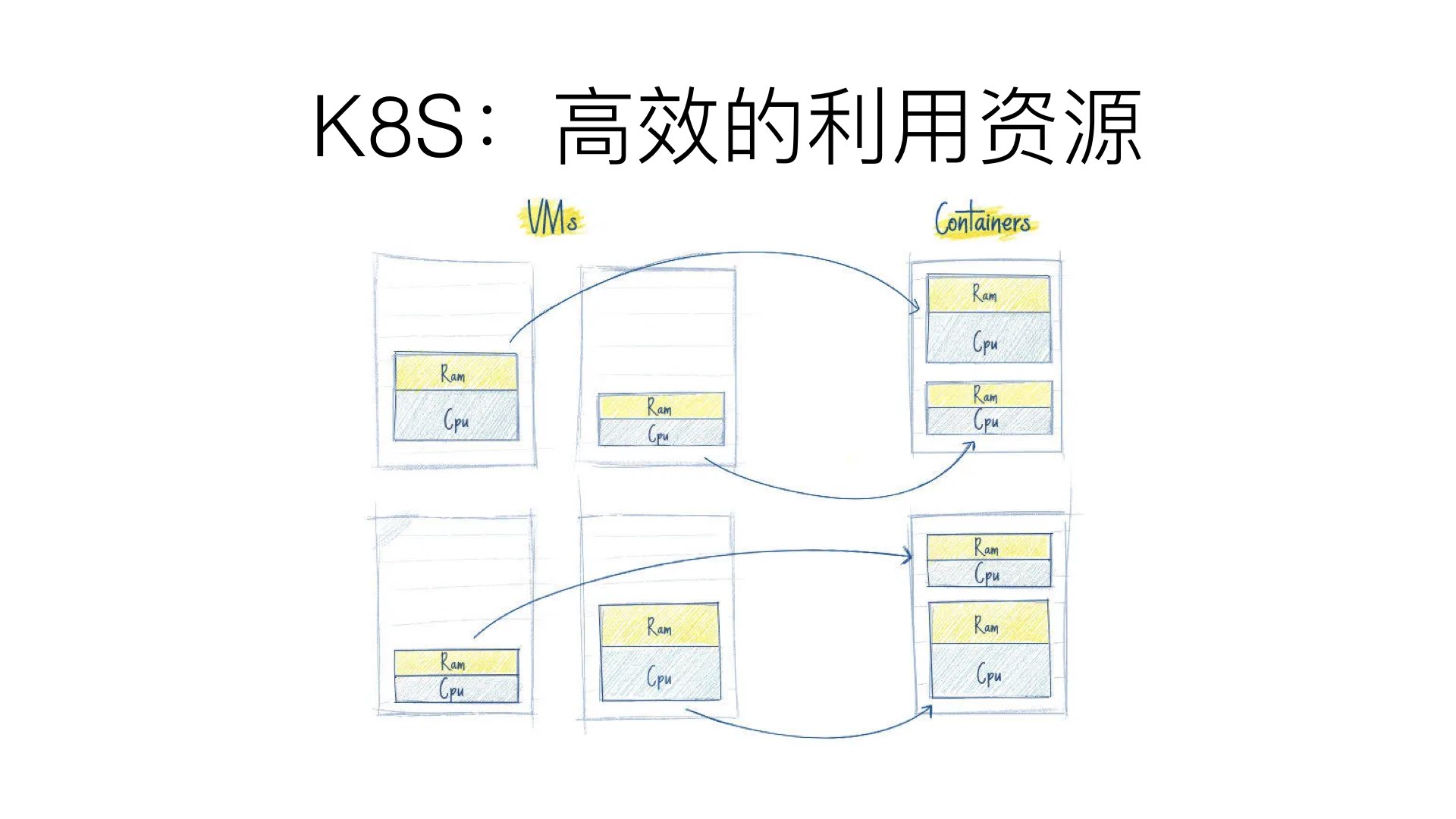
Kubernetes 如果发现有节点工作不饱和,便会重新分配 pod,帮助我们节省开销,高效的利用内存、处理器等资源。
如果一个节点宕机了,Kubernetes 会自动重新创建之前运行在此节点上的 pod,在其他节点上运行。
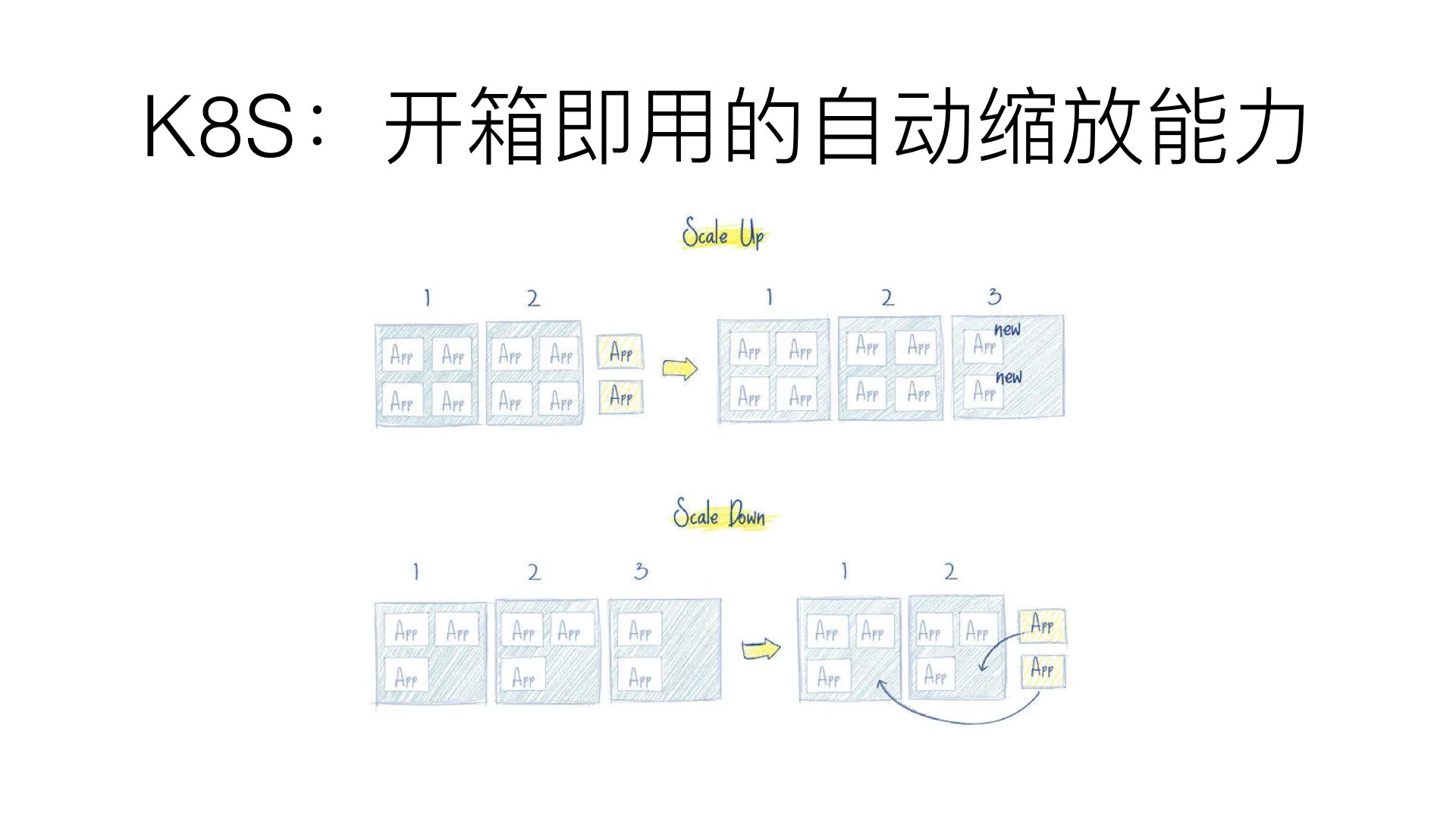
网络、负载均衡、复制等特性,对于 Kubernetes 都是开箱即用的。
pod 是无状态运行的,任何时候有 pod 宕了,立马会有其他 pod 接替它的工作,用户完全感觉不到。
如果用户量突然暴增,现有的 pod 规模不足了,那么会自动创建出一批新的 pod,以适应当前的需求。
反之亦然,当负载降下来的时候,Kubernetes 也会自动缩减 pod 的数量。

利用镜像,从开发到调试到上线一条龙,酸爽。

Kubernetes 如此流行的一个重要原因是:应用会一直顺利运行,不会被 pod 或 节点的故障所中断。
如果出现故障,Kubernetes 会创建必要数量的应用镜像,并分配到健康的 pod 或节点中,直到系统恢复。

完善后的架构。

如果继续发展呢?

上面一排是指导思想,下面一排是具体方案。

计算机领域很重要的思想。

也是很重要的思想。

如果仅用一句话来形容高并发、高可用?副本足以。

IO 复用是节约进程这个资源,让单个进程可以监听多个 fd。

也就是说不要无端提高系统复杂度。

展开分析。

单元化的实现。针对流水型数据,在本单元就消化完成了。 把分流的动作提前到网关处。
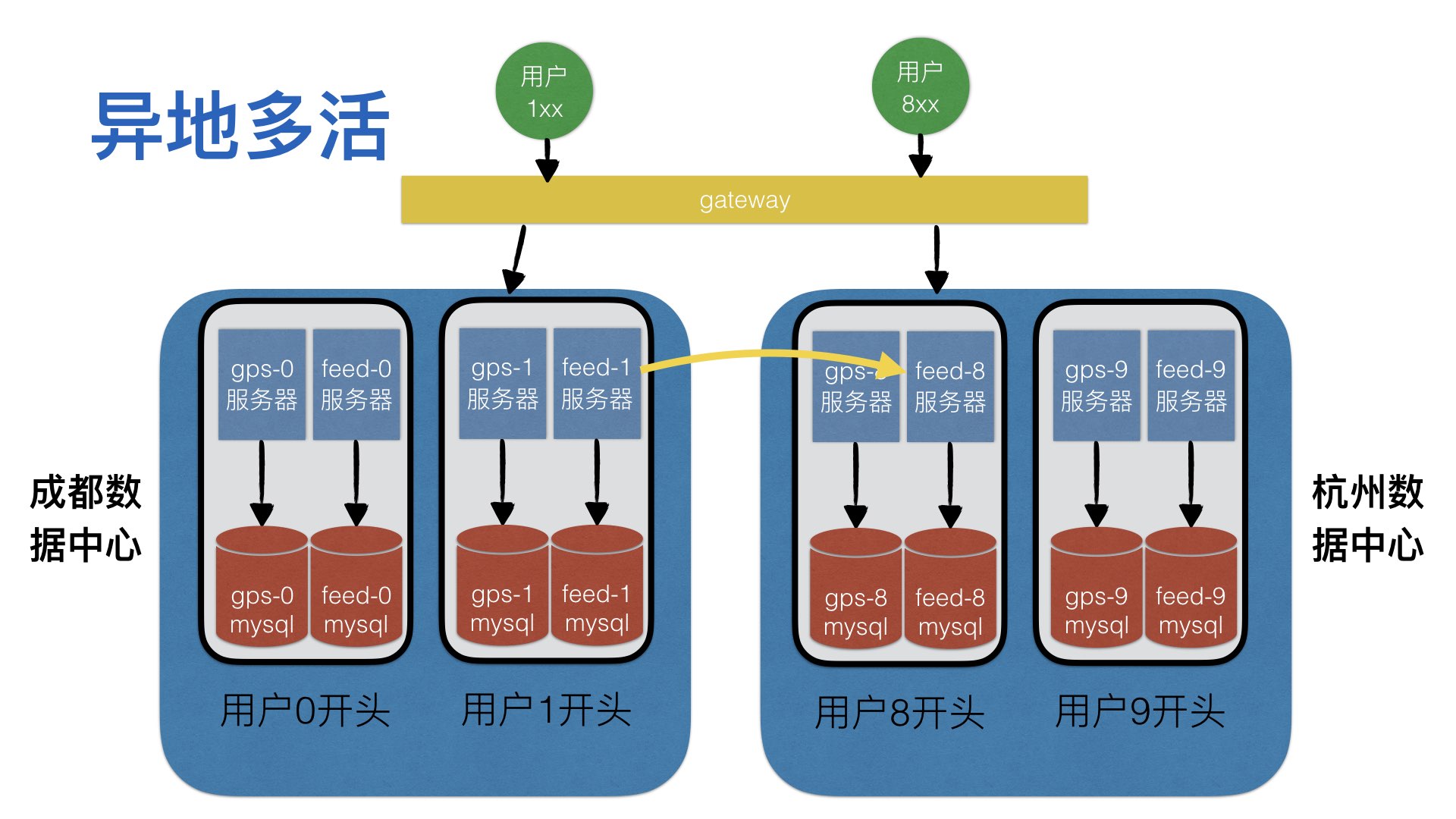
针对共享型数据,则涉及到跨地区的访问。比如三地五中心这种经典架构。
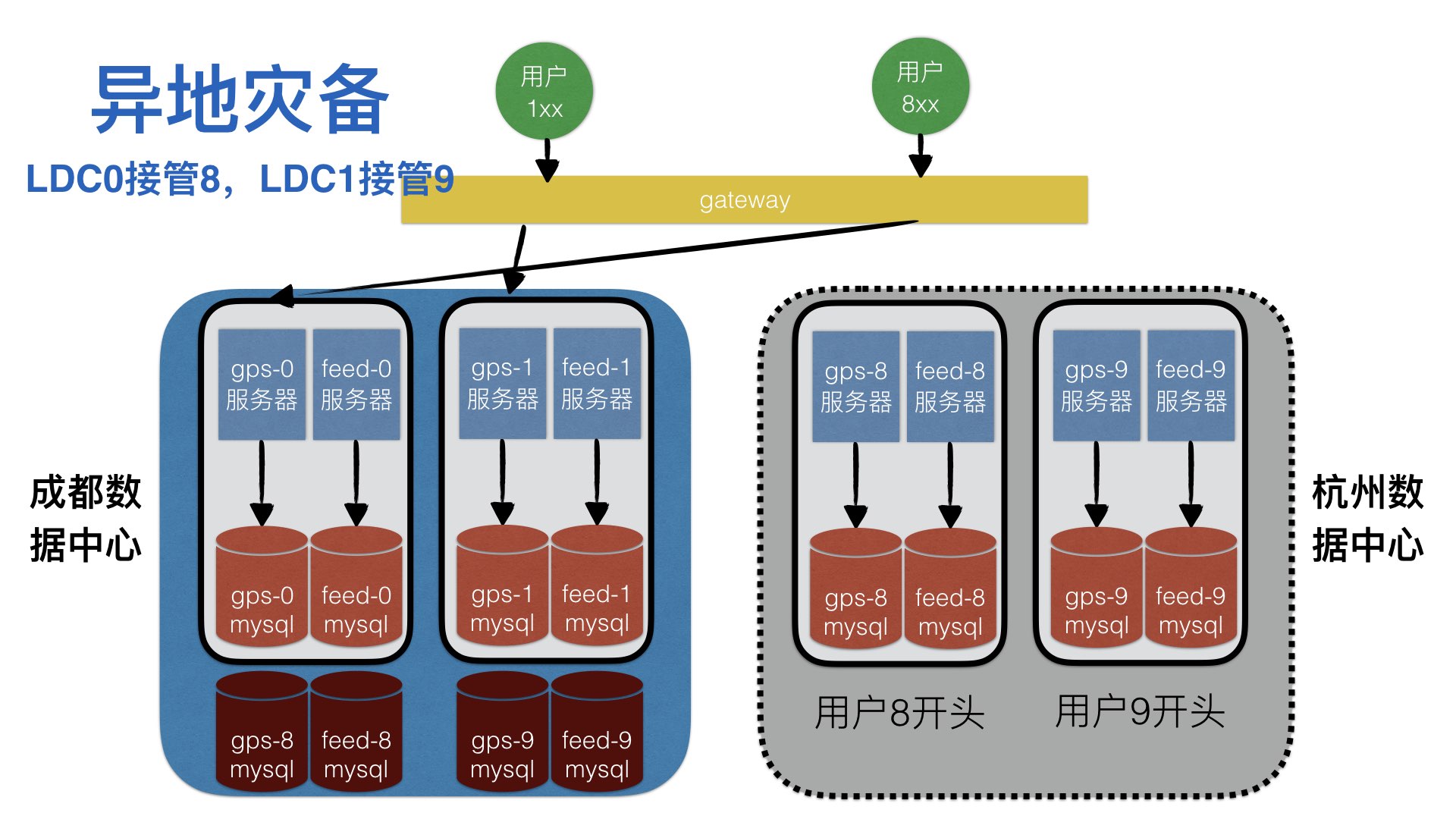
异地灾备的基础是,其他地区的数据也要进行冗余存储。

服务治理的进化方向,此处无法展开。

除了 MySQL 和 PostgreqSQL 我们还有啥。

跨领域的结合。

期待量子计算机。
