前文简述了「领域内的数据一致性」,本文来说一说「领域间的数据一致性」。在业务实践中,特别是在微服务场景下,针对不同场景对一致性不同的要求程度,阐述不同的业务模型。
微服务之间的数据同步模型
下面从一致性逐渐增强的角度,阐述了各种同步模型。当然这只是一个大概的评价,像同步和异步的模式有些情况无法对比。
同步请求
业务场景:最普通的微服务之间的请求模型,常用 RPC 实现(含 http 协议)。上游依赖下游的信息(但不是最核心的信息),不处理失败场景。
模型分析
针对 RPC 的特性,有三种可能
- 请求成功,正常返回(包括业务正确或错误)
- 发起请求阶段网络异常,下游未处理
- 返回请求阶段网络异常,下游已处理
- 有点类似 Unix I/O 模型中的阻塞 I/O
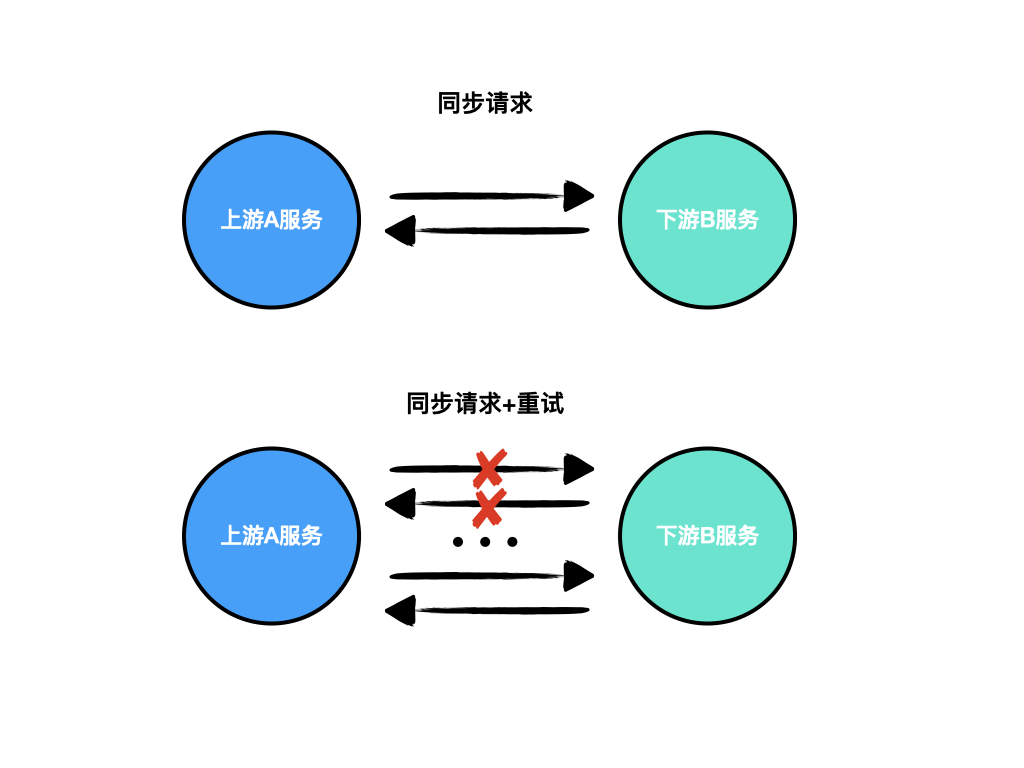
同步请求+重试
业务场景:同步请求失败的情况下(含网络错误或超时),假设是网络抖动引起的,延迟一小段时间后重试。
模型分析
- 重试后依然失败的可以报警人工处理
- 重试次数有限制,重试间隔可以用指数递增
- 多数是读请求,如果是写请求的话需要下游保证幂等性
下图是同步请求及重试的示意图:
同步请求+轮询
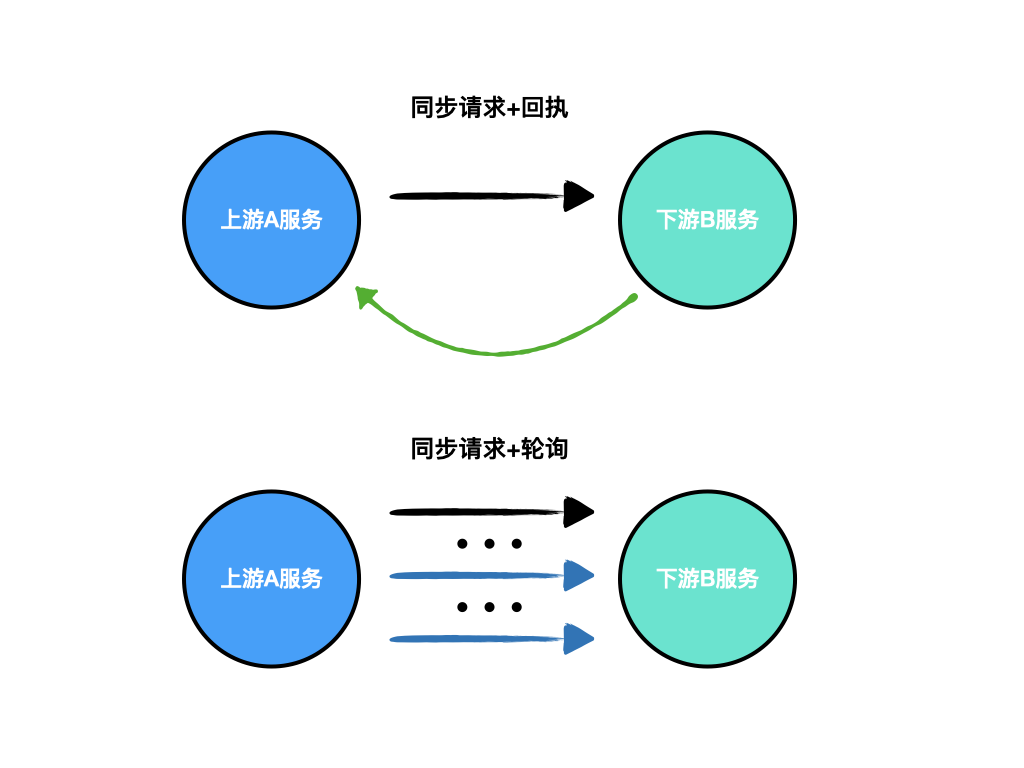
业务场景:针对整体延迟较高的业务场景,上游服务依赖的下游服务处理时间较长,上游服务执意在「同一个会话」中等待同步数据流程完成。比如某些业务需要等待确认支付流程成功,必须在当前会话中轮询。
模型分析
- 下游服务需要在接收到请求时做持久化,提高可靠性
- 下游服务可以在一开始返回一个「业务ID」供后续查询使用
- 轮询间隔时间可以由下游服务指定
- 有点类似 Unix I/O 模型中的非阻塞I/O
同步请求+回执
业务场景:和上述的回执模型类似,下游服务处理时间较长,不同的是下游处理完毕后主动通知上游。
模型分析
- 一般不是用户侧发起的路径
- 也是最终一致性的体现
- 有点类似 Unix I/O 模型中的信号驱动I/O
下图是同步请求+轮询及回执的示意图:
异步队列
业务场景:消息异步处理模式多应用于非核心链路上负载较高的处理环节中,井且服务的上游不关心下游的处理结果,下游也不需要向上游返回处理结果。
模型分析
- 我们工程实践中使用 kafka 作为消息队列
- 实践中 Producer 选择折中的 ack 策略(仅 leader 确认),平衡高并发和高可用
- 实践中 Consumer 选择 oldest 的接入策略和手动 commit 的确认方式,避免服务中途重启可能导致的消息丢失
- kafka 的订阅模式,即同一个 topic 对应多消费者组的模式,很适合单上游多下游的服务模式
异步队列+落表(消息投递系统)
业务场景:在异步的场景下,为了更高程度的保证可靠性,在上游服务(生产者这端)加强通知的有效性,即如果消息队列暂时不响应的话,需要对消息落表保存,待后续异步重试。
模型分析
- 首先对投递方进行失败重试
- 若干次失败后写数据库,等待异步执行的 worker 扫描数据库后重试
- 我们在实践中也遇到过数次 kafka 集群异常重启,整个阶段可能持续数分钟
下图是异步队列及落表的示意图:
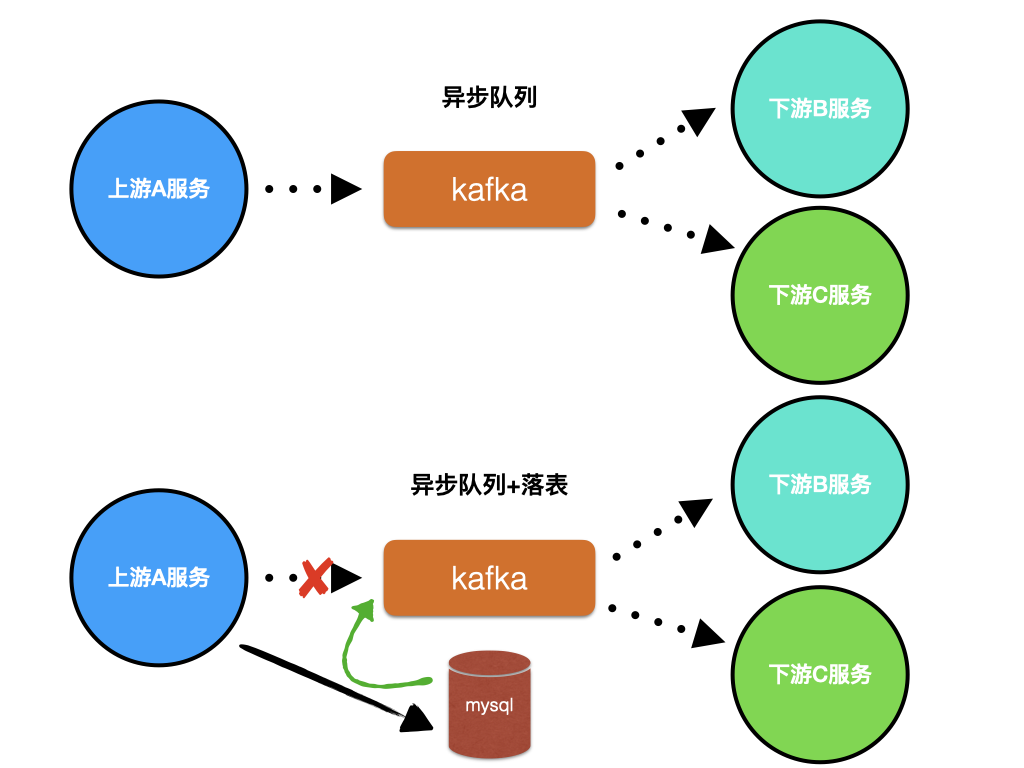
对照我们的 mns 系统。
异步队列+验证(消息确认系统)
业务场景:在前面异步队列+落表的基础上,需要对下游的结果进行验证,以保证业务的可靠性。
模型分析
- 提前注册业务 topic 对应的下游接口和结果验证方式
- 经由上文的「消息投递系统」系统,上游服务将数据投递给本系统
- 本系统与下游服务交互后,通过注册的验证方式判断结果是否正常
- 错误的结果通过队列重试,失败次数过多后落表报警手动处理
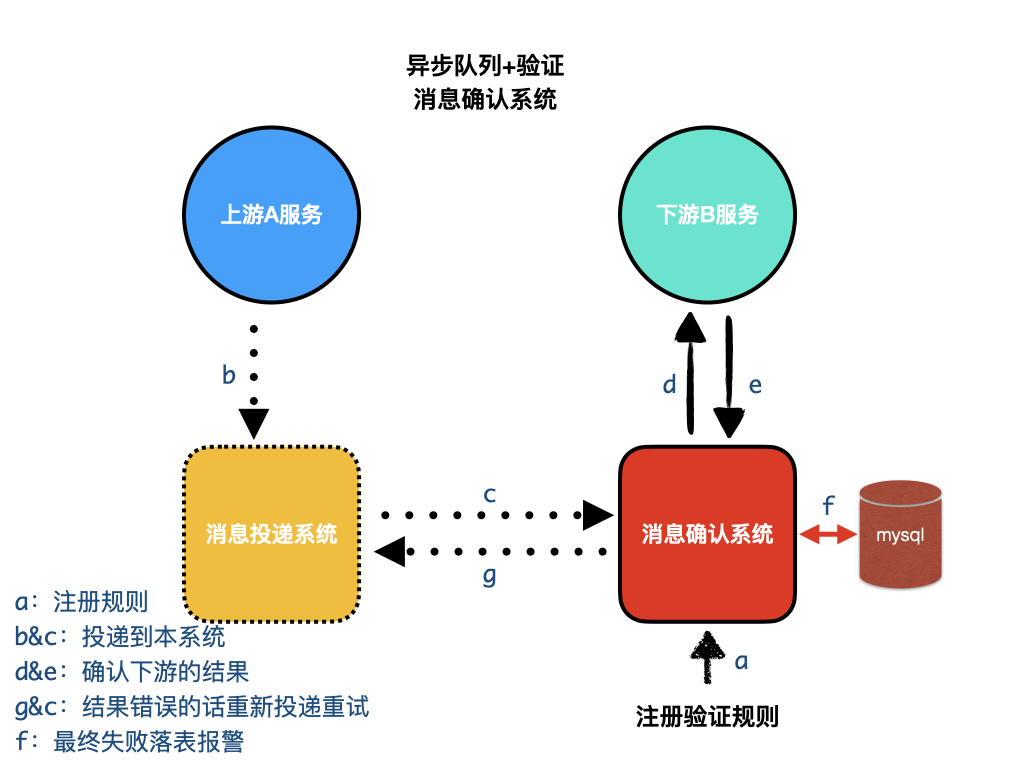
对照我们的 notifier 系统。
同步请求+异步队列结合(请求重放系统)
业务场景:类似「同步请求+重试」的场景,上游服务依赖下游的返回数据,但是把这一套重试的可靠性保证独立出来,形成单独的组件,这样有利于减轻业务服务的负担。
模型分析
- 同步请求失败后,将该请求的参数(含url、param、header等)dump出来
- 经由上文的「消息投递系统」系统,将上面的 dump 信息投递给本系统
- 本系统代替业务服务进行不断重试,并将最终结果返回给上游业务服务
- 失败次数过多后落表报警手动处理

对照我们的 replay_system 系统。
同步和异步的对比
《伸缩性和可用性反模式》和《可伸缩性最佳实战》提到:
同步调用在任何软件系统中都是不可避免的,但是我们软件工程师必须明白同步调用给软件系统带来的问题。如果我们将应用程序串接起来,那么系统的可用性就会低于任何一个单一组件的可用性。比如组件 A 同步调用了组件 B,组件 A 的可用性为 99.9%,组件 B 的可用性为 99.9%,那么组件 A 同步调用组件B的可用性就是 99.9% * 99.9% = 99.8%。同步调用使得系统的可用性受到了所有串接组件可用性的影响,因此我们在系统设计的时候应该清楚哪些地方应该同步调用,在不需要同步调用的时候尽量的进行异步的调用。
不要小看可用性从 99.9% 降到 99.8%,落实到一个月上面,不可用的时间增加了43分钟。
同步调用使得组件和组件之间紧密耦合起来,这样就使得要想伸缩应用就需要伸缩所有的组件,这不仅带来使得伸缩的成本增加,而且这种高度耦合性使得伸缩变得更加困难。因此我们需要从应用角度划分出,哪些业务操作是紧密关联的,哪些是可以异步执行的,划分出那些可以异步执行的操作,然后将其进行异步化处理,这样划分的好处就是系统可以应对更大的访问量,消弱访问峰值,比如在同步的时候 A 调用了 B,那么用户能接受响应时间就是 A 处理时间 + B 处理的时间,而采用异步以后,当访问量增大的时候,因为 A 和 B 异步,那么 A 很快返回,用户体会不到延迟,而 B 的处理时间由原来的2秒处理完毕,变为3秒处理完毕,而 B 得处理都是在后台进行的,不会影响到客户响应事件,同时异步也起到了消弱峰值的作用。
所以建议的做法是:
- 对于短平快的业务,使用同步模型,直接简单
- 对于可靠性要求高的业务,使用异步模型可以提高可靠性
- 对于并发压力大的业务,使用异步模型可以提高伸缩性
怎么保证下游幂等性?
- 用全局唯一ID
- 用业务状态扭转保证(比如电商里的已支付状态不可能扭转回待支付)
为什么业务补偿型不行?
业务补偿模式是一种纯补偿模式,其设计理念为,业务在调用的时候正常提交,当一个服务失败的时候,所有其依赖的上游服务都进行业务补偿操作(取消操作)。
举个例子,小明从杭州出发,去往美国纽约出差,现在他需要定从杭州去往上海的火车票,以及从上海飞往纽约的飞机票。如果小明成功购买了火车票之后发现那天的飞机票已经售空了,那么与其在上海再多待一天,小明还不如取消去上海的火车票,选择飞往北京再转机纽约,所以小明就取消了去上海的火车票。
这个思路可以延续到 2PC 或者 TCC 模型上面。