微服务不是银弹
后端架构演进到微服务模型,带来了很多好处:高内聚、低耦合、资源隔离、弹性服务、交付进度快等。但是同时也带来了不少挑战,原本单体服务中的函数调用,变为服务之间的网络调用。由于网络必然的不确定性,带来服务之间的通信不确定性。
文章《微服务高可用利器——Hystrix熔断降级原理&实践总结》提到:
例如:一个依赖30个服务的系统,每个服务99.99%可用,99.99%的30次方 ≈ 99.7% ,0.3% 意味着1亿次请求会有 3,000,00次失败 ,换算成时间大约每月有2个小时服务不稳定,随着服务依赖数量的变多,服务总体可用性会变得更差。 假设我们当前服务的外部依赖中,有一个服务出现了故障,可能是网络抖动出现了超时,亦或服务挂掉导致请求超时,短时间内看起来像下图这样:
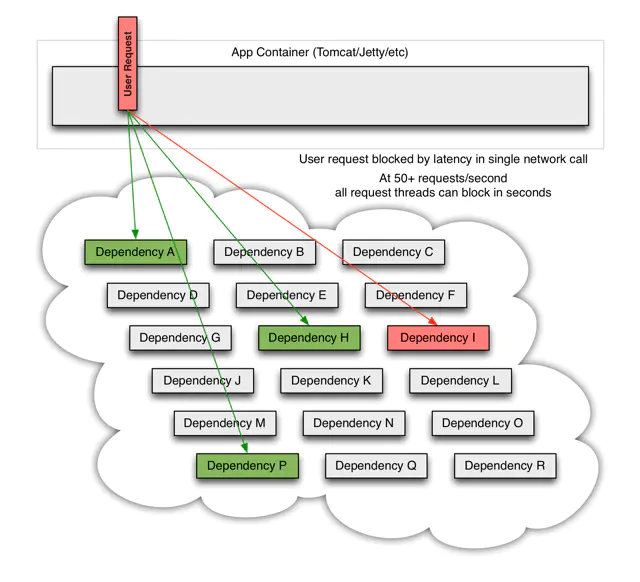
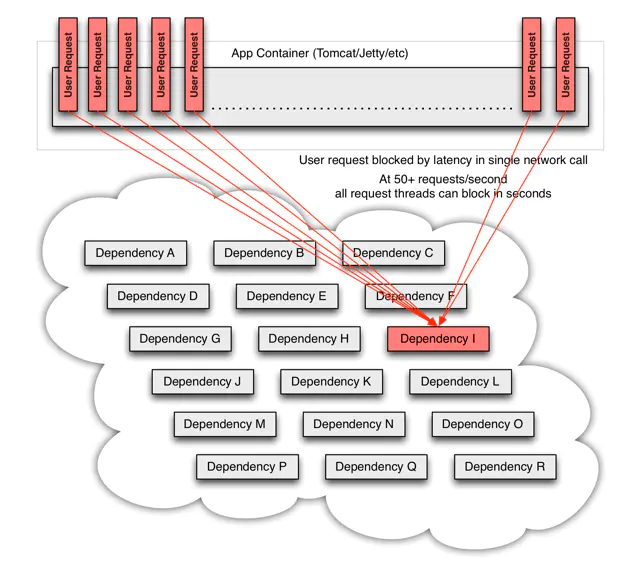
慢慢的大量业务线程都会阻塞在对故障服务的调用上,请求排队,服务响应缓慢,系统资源渐渐消耗,最终导致服务崩溃,更可怕的是这种影响会持续的向上传递,进而导致服务雪崩。
服务治理
现有服务 A 调用服务 B,我们定义 A 为请求者,B 为接受者。在高并发的情况下,接受者可能由于自身计算能力或者数据库 IO 不足的原因无法提供全部服务能力。此时需要引入三种服务治理的手段,尽最大可能地提供全站服务能力,而不是任由接受者被冲垮,导致数据库负载打满,带来整体可用性下降,甚至发生雪崩的危险。
熔断
熔断器是在请求者的角度实施,保护接受者。当请求失败或超时达到一定的阈值时,触发熔断,使得之后的请求者在一定时间内不再发起调用,给予接受者一定的恢复时间,等其恢复正常后再发起调用。这种保护机制大大降低了链式异常引起的服务雪崩的可能性。
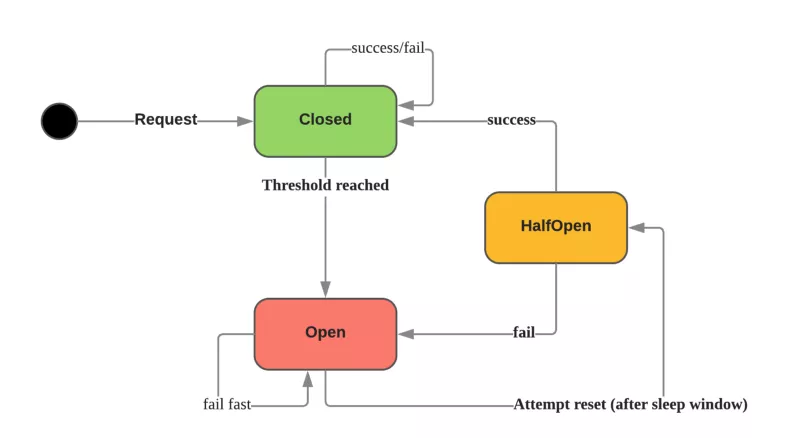
我们实际基于 Netflex 开源的 hystrix 熔断组件进行开发。hystrix 熔断器的核心原理基于滑动窗口实现,每秒创建一个 bucket 进行统计。
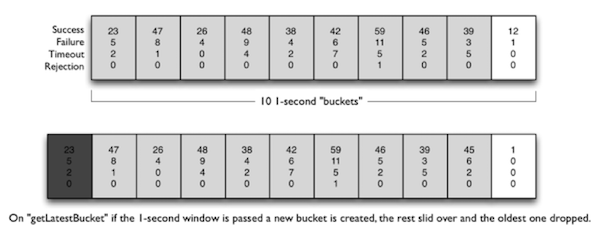
在熔断器里面有3种主要的状态:
-
关闭:让请求通过的默认状态。如果请求成功/失败但低于阈值,则状态保持不变。可能出现的错误是超过最大并发数和超时错误。
-
打开:当熔断器打开的时候,所有的请求都会被标记为失败;这是故障快速失败机制,而不需要等待超时时间完成。
-
半开:定期的尝试发起请求来确认系统是否恢复。如果恢复了,熔断器将转为关闭状态或者保持打开。
降级
我们这里特指手动降级(降级的另一个概念是在熔断触发后,请求者使用预先配置好的默认数据),按照业务的重要性,划分 N 个降级级别,每个级别包含若干接口或者某个微服务的所有接口。当发生大促或者重大活动的时候,根据全站的负载级别,选择打开某些降级级别,减轻系统压力,保证最核心业务的可用。
我们目前的选择是:
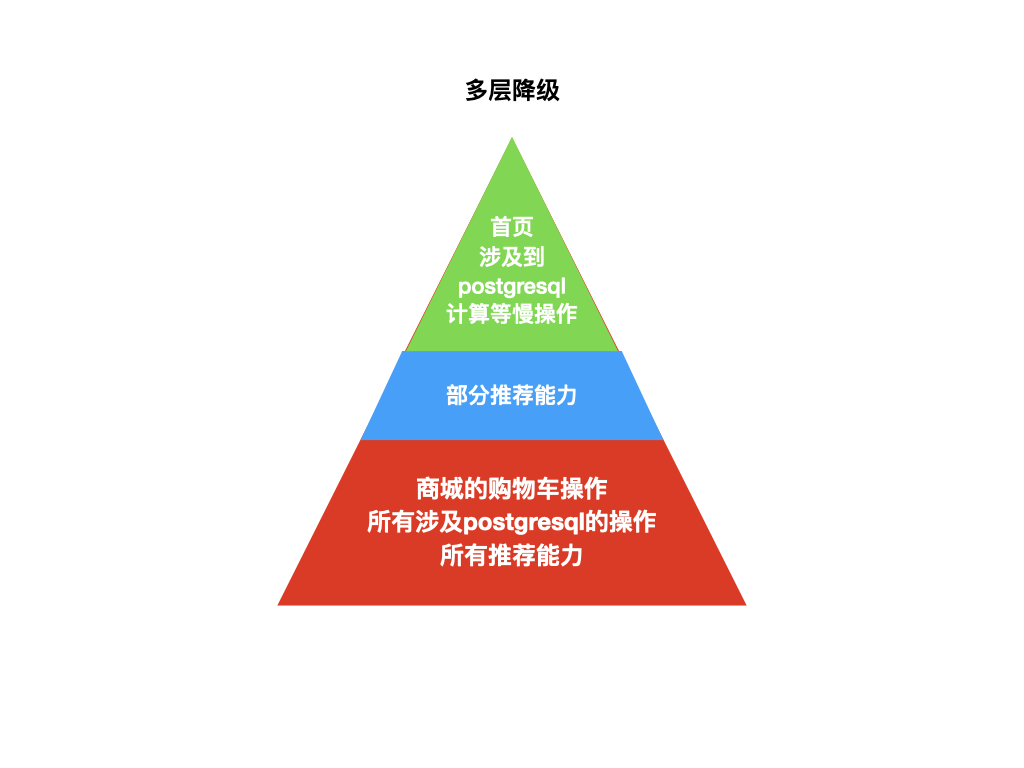
可以看到降级是站在全站的角度,依次放弃不很重要的业务,保证系统核心能力,是一种业务和技术的妥协。
代码实现较为简单,利用 etcd 的 watch 功能,所有的请求者可以在同一时间打开降级开关,让调用直接返回。
限流
限流是站在接受者的角度来考虑,因为接受者自己最清楚自己能力的极限,一般通过压测来估算。如果站在请求者的角度来考虑,就有以下问题:
- 不知道接受者的能力极限
- 需要知道请求者自己实际部署情况(多少个pod),带来复杂度
- 不知道还有没有另外的请求者,无法真实评估
我们基于阿里开源的sentinel-golang,在 gin 框架封装限流的middleware。提供 QPS 和 并发数两种流控指标,以及两种控制效果:
- 直接拒绝(Reject),当前的请求量超过对应规则的阈值后,新的请求就会被立即拒绝。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。
- 匀速排队(Throttling)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。多余的请求可以排队等待而不是立即拒绝。

详情可见wiki。
{kind=link}
值得注意的是,在计算限流配置的时候,一般从数据库压力入手。假设 Mysql 的极限 QPS 是1000,这个微服务有10个pod,那么限流的配置应该是 100 QPS
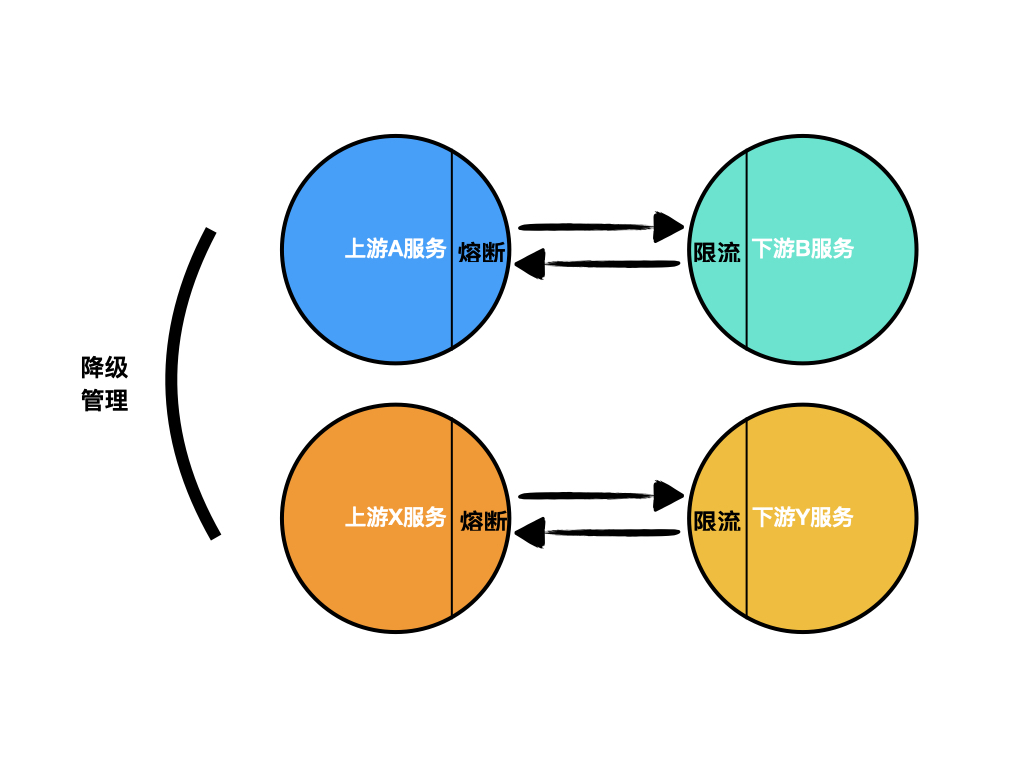
整体模型
综上所述,微服务治理使用到了熔断、降级、限流等多手段,努力将系统提供的服务能力平稳化。
- 上游不想被下游拖垮,使用熔断(同时也保护了下游)
- 下游不想被上游击垮,使用限流
- 全局的控制,使用降级