本文以我个人视角记录了近三年在AI SRE领域的回顾。核心主线是:2024年解决「AI能不能做SRE」的问题,2025年解决「怎么做成产品」的问题,2026年解决「怎么让更多人参与共建」的问题。从EKG图谱推理到DeRisk平台,再到MCPs/SKILLs/SPECs生态体系,每年都在前一年的地基上往上盖楼,方向一致,也有不少弯路和妥协。
一句话定义
AI SRE,是用大语言模型和智能体技术重构站点可靠性工程的全新范式——让AI成为7×24小时在线的数字SRE队友,从告警响应、根因定位到故障自愈,逐步接管传统SRE的重复性劳动,最终实现「人负责决策,AI负责执行」的协同模式。
我们的纵向演进:三年三个阶段
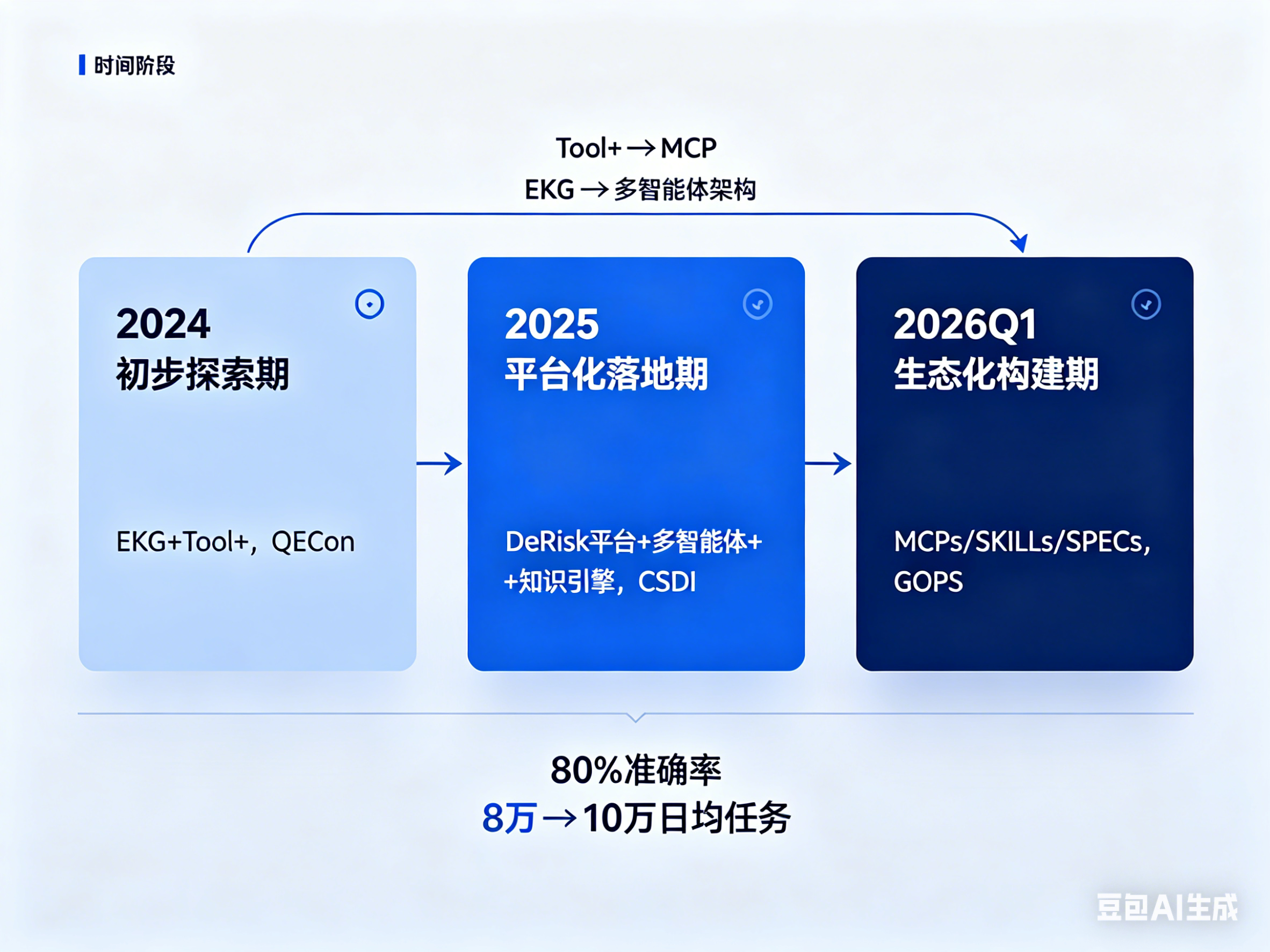
我们在AI SRE领域的探索,从2024年到2026年,大致经历了三个阶段。2025年之前,我们做了不少零散的实践和尝试(包括EKG等),积累了一些经验教训;2025年正式开始做DeRisk平台,把之前的探索整合起来。每一次对外分享,技术路线和产品形态都有变化。回头看,有些方向判断是对的,有些具体方案走了弯路,但整体上是在不断迭代和修正中往前走的。
阶段一:初步探索期(2024,QECon上海站)
背景与起点

2024年,我在QECon上海站做了第一次系统性对外分享,题目是「蚂蚁集团基于LLM的SRE智能体落地实践」。
这个时间点有一个很重要的背景:2024年的LLM推理能力还相当有限。ChatGPT在2022年底爆发,2023年全行业都在探索LLM的应用场景,但当时的模型在复杂多步推理上表现不稳定,尤其是在运维这种需要严谨逻辑链的领域,直接让LLM做端到端的推理决策,效果远不够可靠。行业的普遍做法是「套一个RAG做知识问答」,我们当时的判断是:SRE领域是严谨、专业、私有的,通用LLM给出的只能是泛泛之谈,核心突破口不在RAG,而在Planner。
现在回头看,这个方向判断是对的,但具体的技术方案受限于当时的LLM能力,做了不少妥协。
核心技术:EKG + Tool+ + Code+
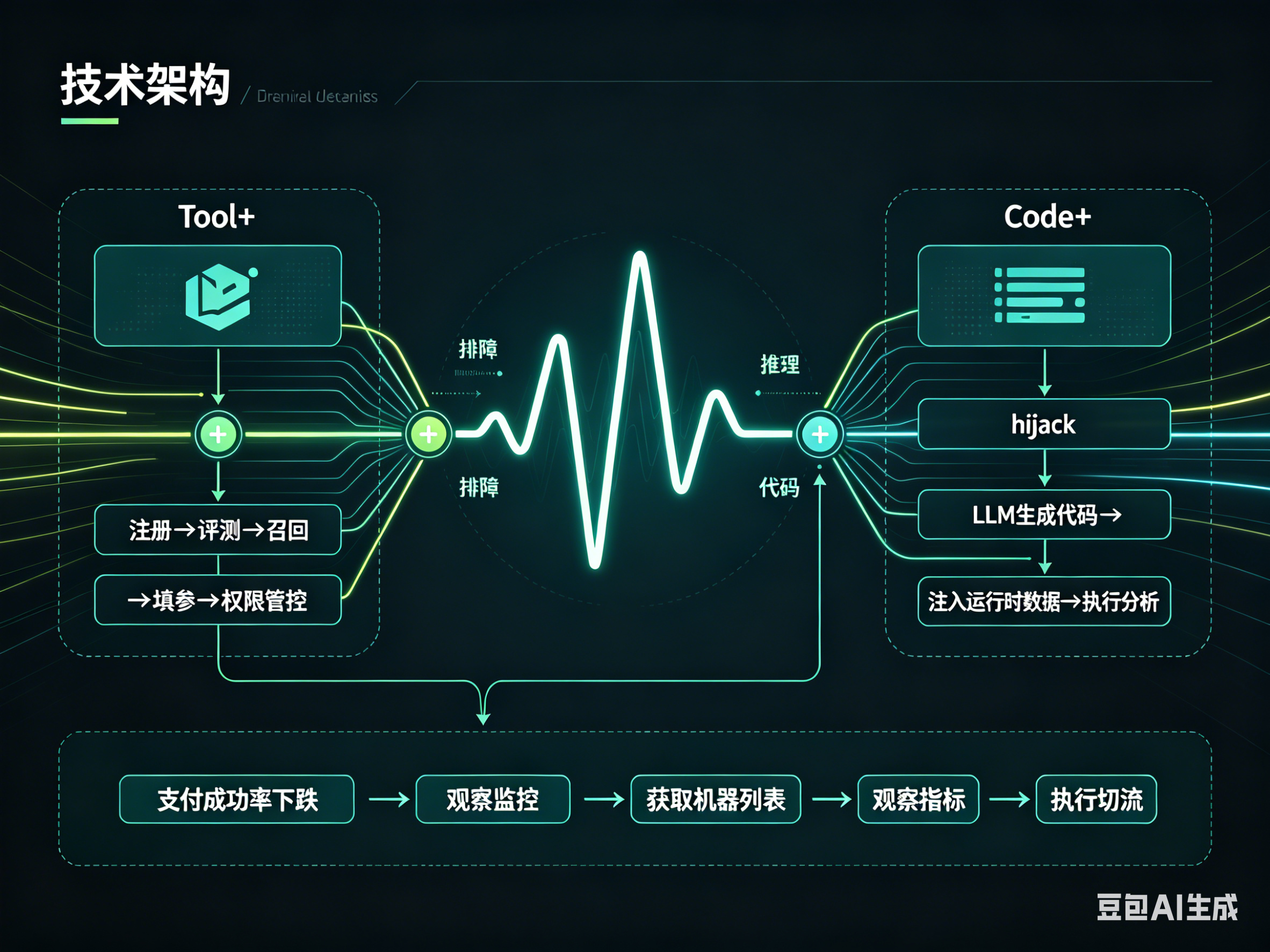
EKG(Eventic Knowledge Graph,事件知识图谱) 是这一阶段的核心探索方向。它的出发点很务实:既然2024年的LLM无法可靠地完成复杂的多步推理,那我们就用结构化的图谱来「托底」——把专家的排障经验编码为图结构,让Agent沿着图谱路径执行,而不是完全依赖LLM的自主推理。
相比于普通的workflow/pipeline,EKG有一些自己的特色:它支持并发多线程调度(SRE排障天然是并行的——同时查监控、查日志、查变更),携带context、route history、tool history三层记忆,比线性DAG更灵活。但说实话,EKG本质上还是一种预定义的流程编排,和普通workflow的差距没有我们最初期望的那么大。图谱的构建和维护成本不低,而且面对真正复杂的、超出图谱覆盖范围的场景,EKG同样力不从心。
一个我们当时展示的典型场景:「天猫海外支付成功率下跌怎么办?」通用LLM给出的是泛泛的建议,而基于EKG的SRE智能体能走出一条具体的排查路径——选Tool观察业务监控 → 获取负载机器列表 → 观察相关指标变化 → 执行应用切流 → 排查压测流量。这确实比纯LLM的效果好,但这种效果更多来自于预置的专家经验图谱,而非模型自身的推理突破。
Tool+ 解决的是工具调用的工程化问题。不只是让LLM能调API,而是从注册(OneAPI一键录入)、评测(单Tool/多Tool单步/多Tool多步三级评测)、到执行(query改写 → 多轮信息获取 → Embed/LLM召回 → 填参 → 参数校验 → 权限管控)的完整链路。高危场景有人工确认机制,SQL查询支持二次编辑后再执行。
Code+ 的亮点是「代码hijack」——LLM生成分析代码后,在执行前注入真实运行时数据(比如实时监控数据),让静态代码变成针对真实环境的分析代码。这个设计巧妙地解决了「LLM不知道当前环境状态」的问题。
产品化思路:30-60-10公式
这一阶段提出了一个务实的产品化公式:极简模式(解决30%问题)+ 高阶模式(解决60%)+ 评测管理(解决10%)= SRE智能体Release。
不追求一步到位,先用AgentBasic(预置EKG/RAG/Tool)快速覆盖简单场景,再用AgentPro(复盘文档抽取、text2graph转化、团队工具注册)解决高阶场景,最后用AgentBench做系统性评测把关质量。
关键成果
- 应急复盘工作量减轻80%
- 明确了SRE数字员工的架构方向:全局风险知识图谱 → SRE团队知识图谱 → 各平台Agent(自愈/资金/PaaS等)
这个阶段的核心洞察
回头看,2024年Tool+的完整工程化链路(注册、评测、权限管控)在后续两年持续复用,成为我们的基础设施底座。
但也要诚实地说,EKG作为具体的Planner实现方案,是特定时期的产物。它本质上是用图谱结构来弥补LLM推理能力的不足——这在2024年是合理的工程选择,但随着2025-2026年LLM推理能力的大幅提升(尤其是o1/DeepSeek-R1等推理模型的出现),这种「用结构化图谱替代模型推理」的思路逐渐让位于「让模型自己思考+工具调用」的更灵活范式。这也是我们后来演进到DeRisk平台的内在驱动力之一。
其他不足:产品形态还比较单一(主要是Web和钉钉),多智能体协同还停留在架构设想阶段。
阶段二:平台化落地期(2025,CSDI Summit)
从SRE智能体到DeRisk平台

2025年的CSDI峰会,分享主题变成了「DeRisk AI原生的智能运维平台实践」。从「SRE智能体」到「DeRisk平台」,我们开始尝试把之前两年零散的实践整合成一个相对完整的产品。
DeRisk的含义是:就像DeBug是找Bug、修Bug,DeRisk要做的是找Risk、分析Risk、解决Risk。定位是「为每个应用系统提供7×24小时的AI系统数字管家」。能不能真正做到这个定位,其实到今天我们也还在验证。
三层智能演进路线
这一阶段提出了清晰的三层演进路线:
基础智能:结合LLM + 技术风险,解决领域知识理解、数据、工具使用等痛点,具备基础的风险分析和处理能力。技术上用RAG + DeepResearch。
中级智能:通过模型蒸馏与持续优化,提升精度与效率。业务上实现自主风控准确定位、分析、诊断。这是从「辅助」到「半自主」的跨越。
高级智能:构建基于场景自适应学习的闭环,从被动响应到主动探测、学习、防御、总结、进化。这是终态愿景。
多智能体架构的工程化
2024年的EKG更多是理论和初步实践,到2025年我们开始尝试把多智能体架构做实际的工程化落地。
组织形式上支持三种模式:Supervisor模式(每个Agent只与一个Supervisor通信)、Hierarchical模式(多层Supervisor)、Network模式(节点间互相通信)。
记忆体系对应人类记忆做了完整映射:感知记忆(Sensory Memory)→ 单条消息;短期记忆(Working Memory)→ 多条消息组成的session;长期记忆(Long Term Memory)→ 跨时间周期的报告汇总体系。
最有意思的是空间组织的设计——TeamMode(子Agent只能看到master指令,单线单聊)和GroupMode(子Agent能看到其他Agent的结论,群聊模式)。这两种模式在实际场景中的差异很大:应急诊断用GroupMode,让各维度的分析Agent互相参考结论;独立任务用TeamMode,避免信息污染。
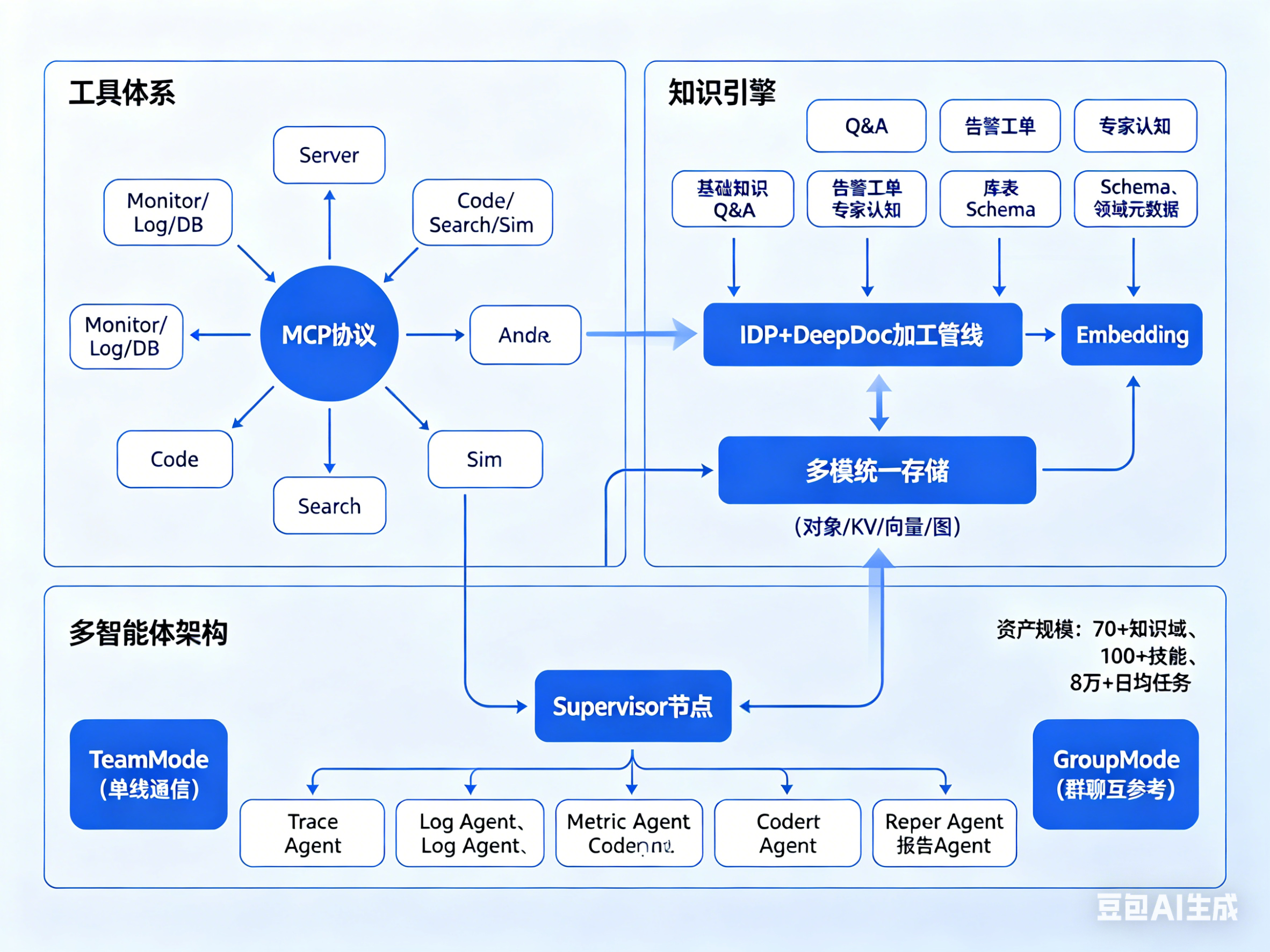
运维资产积累:知识引擎与工具体系
这一阶段我们花了很大力气做运维资产的系统性积累,这是AI SRE落地的基础工作,也是容易被低估的一环。
知识引擎方面,我们搭建了基于IDP(Intelligent Document Processing)+ DeepDoc(深度文档理解)的知识加工管线。可信知识的来源覆盖了六大类:基础知识(技术书籍、项目文档)、Q&A文档(答疑文档、咨询文档)、告警与工单(告警分析处理、异常处理、风险分析文档)、专家认知(领域专家、大佬见解、专业文章/Paper)、库表Schema(Schema、Table、Column、MetaData)、领域元数据(业务链路关系、应用信息等基础元数据)。
知识加工的流程是:知识块处理 → Summary → Tag → 抽取实体/关系图,经过Embedding和Schema Linking后,存入多模统一存储(UnifiedStorage,支持对象、KV、向量、图四种存储模式)。在检索侧,我们实现了混合检索策略(向量相似度匹配、BM25召回、条目权重、关键字、GraphRAG),配合多路知识召回融合和排序。坦率说,这套知识引擎的建设周期比预想的要长,知识质量的把控一直是痛点。
工具体系方面,我们基于MCP协议构建了技术风险领域的工具集,覆盖Metrics、Trace、Log、Code、Change等核心数据源。通用MCP Server由平台团队与各横向平台团队联合共建,包括Monitor-Server(对接监控平台)、Log-Server(对接SLS)、DB-Server(对接DB PASS)、Code-Server(对接AntCode)、Search-Server(对接内外网搜索)、Sim-Server(对接仿真环境)等。
资产规模:到2025年,内部知识体系覆盖了70+领域,内部技能支持超过100+。这些数字看起来还可以,但距离覆盖蚂蚁内部所有技术风险场景还有很大差距。
实践案例:DeepRCA
DeepRCA(深度根因分析)是这一阶段的标杆场景。架构是RCA master调度Trace Agent、Log Agent、Metric Agent、Coder Agent和报告Agent。
构建方法论四步走:定义问题 → 构建知识和技能 → 从单个子智能体开始调试 → 组建多智能体体系。这套方法论在后续被反复验证。
规模数据
| 指标 | 数据 |
|---|---|
| 日均总任务量 | 8万+ |
| 日均Token调用量 | 突破3.5亿 |
| 月Token消费 | 突破100亿 |
| 内部知识体系覆盖 | 70+ |
| 内部技能支持 | 100+技能 |
阶段三:生态化构建期(2026年Q1,GOPS深圳站)
2026年4月的GOPS深圳站,分享主题是「基于MCPs/SKILLs/SPECs的AI风险智能体系演进路径」。这个标题本身就是一个体系性的声明。

MCPs/SKILLs/SPECs:三层分工协作体系
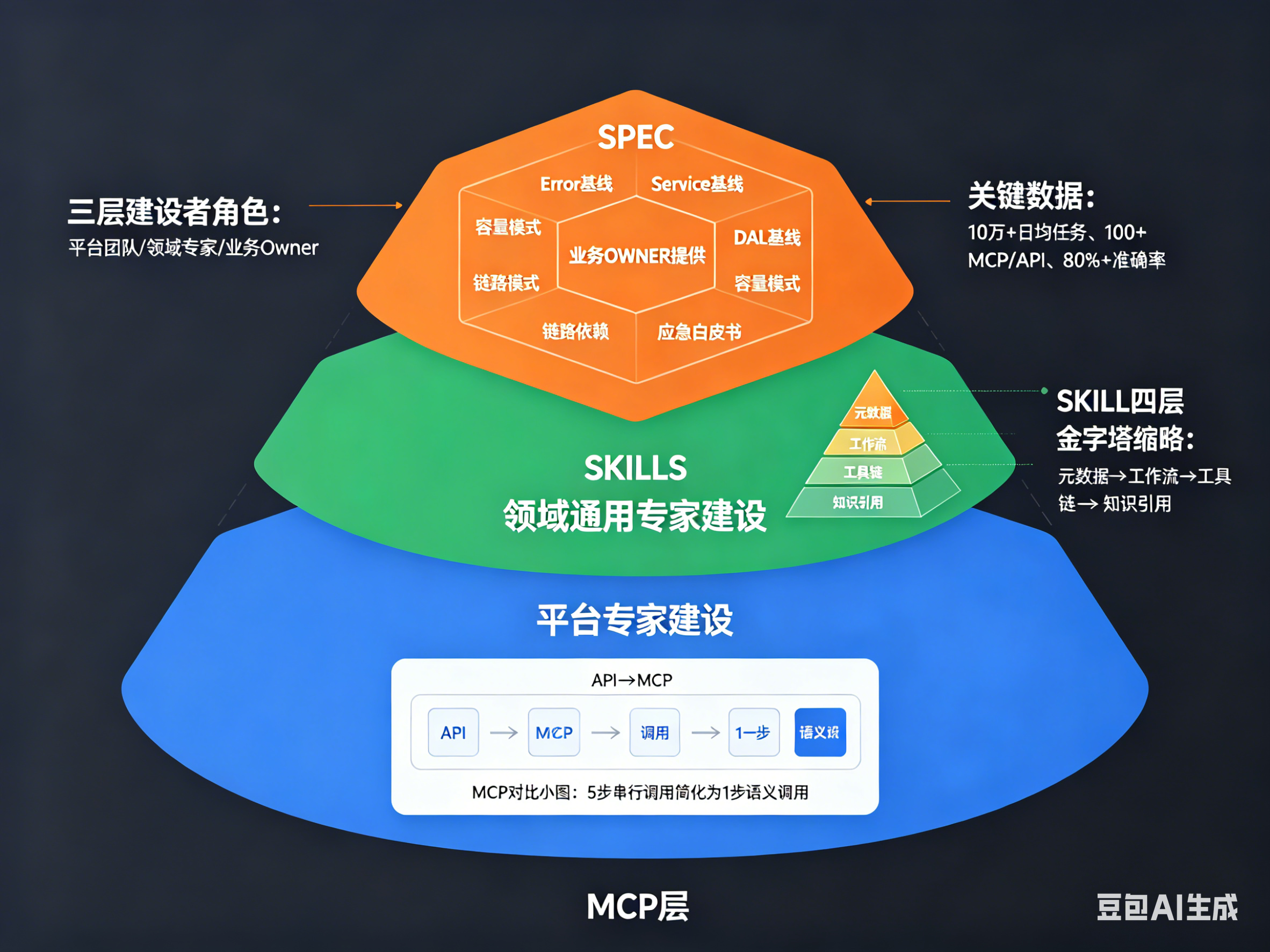
三层体系的分工:
MCP层(平台专家建设):负责整体系统架构设计与维护,构建通用MCP/TOOL,覆盖监控平台、变更平台、运维平台、应急平台。这是基础设施层。
Skills层(领域通用专家建设):负责各个技术风险领域的SKILL与知识维护,覆盖监控SKILL、性能风险SKILL、容量风险SKILL、变更风险SKILL。这是领域知识层。
SPEC层(业务个性专家/OWNER提供):维护业务相关的知识和tool,确保技能和工具符合业务需求。这是业务定制层。
MCP:Agent的UI
这一阶段我们提出了一个观点:「MCP工具是Agent的UI」。
传统API设计是给程序员用的——技术参数、原始数据、细粒度单一操作。MCP的设计要像给Agent用的界面——语义参数、结构化洞察、粗粒度完整场景。
一个具体的对比:查询服务健康状态。API方式需要5步调用(查服务ID → 查指标列表 → 查指标数据 → 自行计算聚合 → 组织回复),MCP方式1步搞定(query_service_health(service="order-service")直接返回health_score和insights)。
这个思路在实践中确实带来了不少便利,算是一个有价值的设计方向。
SKILL的四层金字塔
SKILL被定义为四层结构:
- 元数据(顶层):技能身份标识、版本、适用场景
- 工作流定义:步骤分解、决策逻辑、异常处理
- 工具链声明:执行工作流所需的MCP工具集合
- 知识引用(底层):支撑决策的领域知识和案例库
SKILL与MCP的关系是:SKILL是操作手册(上层编排、有状态、跨步骤记忆),MCP是工具箱(底层执行、无状态、单次调用)。知识工程的三步转化——隐性经验显性化、显性知识结构化、结构知识程序化——就是通过SKILL体系落地的。
SPEC:应用画像的探索
SPEC(Service Profile for Emergency Control)是这一阶段我们比较看重的一个技术方向。
SPEC不是一次性配置文件,而是持续从应用代码、监控指标、配置、发布记录、运营水位中自动抽取并更新的应用知识快照。它包含六个维度:Error基线、Service基线、DAL基线、容量模式、链路依赖、应急白皮书。
SPEC解决的核心问题是「AI不了解具体业务」。有了SPEC,DeRisk Agent在分析任何一个应用的问题时,都有完整的业务上下文可用——不需要SRE口头解释「这个服务是干什么的」「它的上下游是谁」「正常水位是多少」。
这是我们尝试从通用AI走向专属AI-SRE的一个思路。在这次GOPS大会上,我没有看到其他公司有类似的设计,但这也可能是因为大家选择了不同的路径来解决同一个问题。
三层专家协作体系
个人域(孵化试验区)→ 成熟后迁移至正式域
↓
业务个性专家层(国际支付/数字科技/线上支付...)
↓
领域通用专家层(监控/变更/容量/性能/应急/数据库...)
↓
平台专家层(DeRisk平台/监控平台/数据平台/Sandbox...)
这个体系的设计初衷在于:每一层的建设者不同(平台团队 vs 领域专家 vs 业务owner),但通过MCPs/SKILLs/SPECs的标准接口协作。它试图解决AI运维落地的一个核心组织难题——不能指望一个中心化团队理解所有业务场景,必须让业务方参与共建。这个思路对不对,还需要更长时间的验证。
实践案例亮点
SKILL+Browser实践:审批助手检测到ODC审批链接,通过SKILL指挥Sandbox的browser工具完成智能审批。这是SRE日常高频低风险审批的自动化。
SKILL并行实践:emergency-diagnosis-trigger作为调度器,识别问题类型后并行调用通用故障定位skill,传入不同诊断参数,将多维度结果整合为一份报告。追求1-5-10(1分钟发现,5分钟定位,10分钟恢复)。
SKILL+Script+密钥托管:Script配套derisk-mist安全托管AK等敏感信息。灵活性与安全性兼得。
规模数据(2026年Q1)
| 指标 | 数据 |
|---|---|
| 日均任务处理量 | 10万+ |
| 服务时长 | 7×24小时 |
| MCP/API支持数 | 100+ |
| 接入渠道 | Web/钉钉/SDK/API |
智能原生风险体系Pipeline
对于刚起步的企业,我们给出了未来18-36个月的一个初步路线图建议:
| 阶段 | 时间 | 内容 |
|---|---|---|
| 01 工具增强期 | 当前~6个月 | Copilot模式,告警摘要/报告生成/根因辅助 |
| 02 智能SOP | — | 基于LLM的运维SOP,自动化和反馈机制 |
| 03 能力重构期 | 6~18个月 | 基于MCP/Skills/SPECs重构,Agent协作网络 |
| 04 自进化系统 | — | 从新故障中自动学习,从成功案例提取Skills |
| 05 智能原生期 | 18~36个月 | 全面AI Native,跨域协作,持续自我进化 |
三年演进的核心脉络
把三年串起来看,有一条清晰的演进主线:
2024年解决的是「AI能不能做SRE的事」的问题——答案是能,但不能用ReAct线性推理,要用EKG图谱推理;不能用通用工具调用,要用Tool+工程化体系。
2025年解决的是「怎么把它做成产品」的问题——从单点智能体到DeRisk平台,多智能体架构工程化落地,知识引擎和工具体系的系统性建设为后续打下了基础,日均8万+任务验证了产品可行性。
2026年Q1解决的是「怎么让更多人参与共建」的问题——MCPs/SKILLs/SPECs三层体系让平台团队、领域专家、业务owner各司其职,SPEC让AI真正理解每个应用的业务上下文,日均10万+任务证明了规模化的可能。
每一年的进化都不是推倒重来,而是在前一年的地基上往上盖楼。2024年的Tool+体系在2026年Q1进化为MCP层,2024年的EKG在2025年进化为多智能体架构,2025年积累的知识引擎和工具体系在2026年Q1具象化为MCPs/SKILLs/SPECs三层协作框架。
总体来说,方向是一致的,每一年都在前一年的基础上迭代。当然,这里面也有不少弯路和妥协,并没有听上去这么顺畅。